Elder Scrolls 5: Skyrim Special Edition
The Elder Scrolls 5: Skyrim Special Edition — это переиздание ролевой фэнтезийной игры с открытым миром The Elder Scrolls 5: Skyrim Legendary Edition... Детальніше
xVASynth 2 - SKVA Synth - інструмент для озвучування
-
www.nexusmods.comЗавантажити
xVASynth 2 - SKVA Synth.
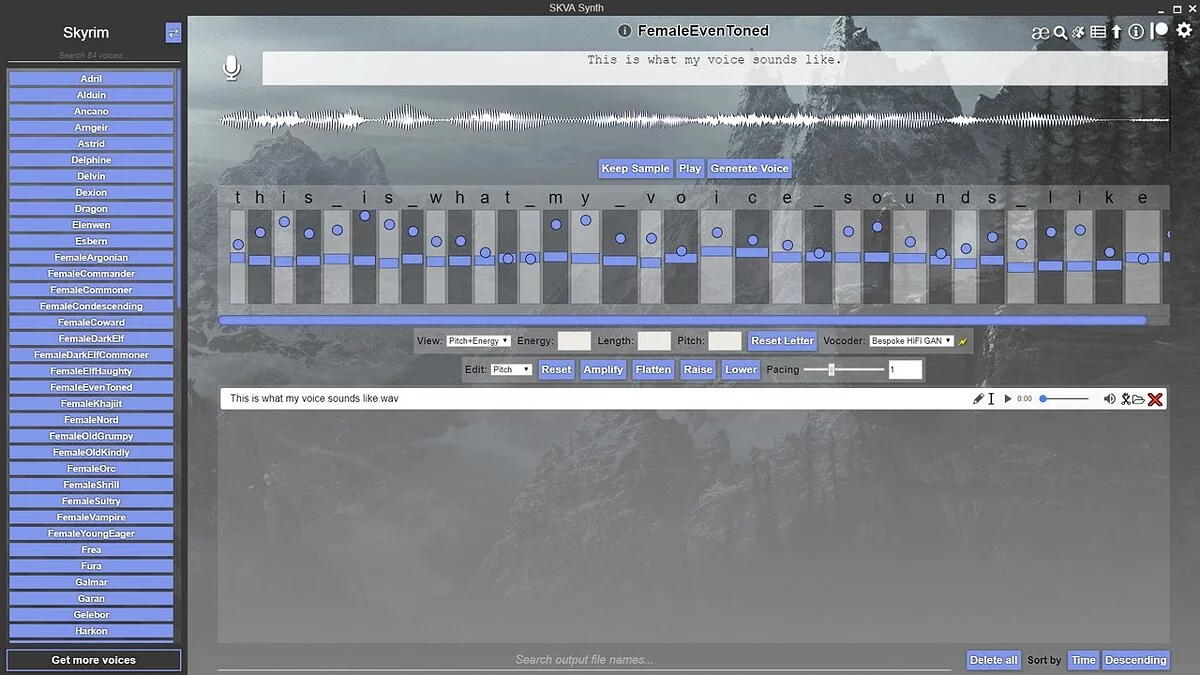
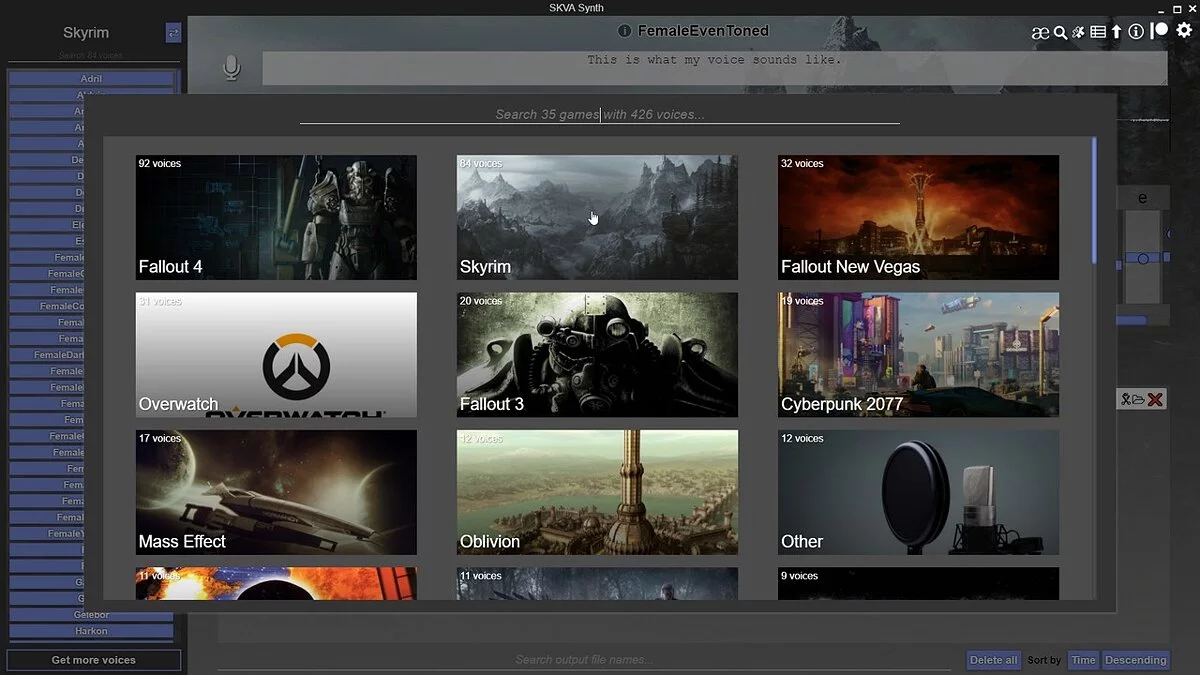
xVASynth – це інструмент штучного інтелекту для створення високоякісних реплік озвучки з використанням голосів із відеоігор. Програма підтримує сотні голосів у десятках ігор та забезпечує керування висотою тону, тривалістю та енергією з точністю до кожної літери.
Вступ
xVASynth (або [SK]VASynth, для голосів Skyrim) — це програма зі штучним інтелектом, яка генерує репліки озвучки, використовуючи певні голоси з відеоігор. Він може перетворювати текст на мову (TTS) з текстового введення або мову на мову (S2S) з аудіовходу. Програма використовує моделі FastPitch [1,2], які дають користувачам художній контроль над висотою тону, тривалістю та значеннями енергії (тільки моделі v2+) для кожної літери в аудіо. Вони також дозволяють генерувати звук із явно заданою вимовою через нотацію ARPAbet.
Використання нейронного синтезу промови призводить до природного звучання голоси, що дуже складно зробити за допомогою традиційніших методів, що включають поєднання існуючих даних. Це також означає, що може бути згенерований новий словниковий запас, крім того, що актори озвучування вже прочитали.

xVASynth 2 — SKVA Synth.
xVASynth — это инструмент искусственного интеллекта для создания высококачественных реплик озвучки с использованием голосов из видеоигр. Приложение поддерживает сотни голосов в десятках игр и обеспечивает управление высотой тона, продолжительностью и энергией с точностью до каждой буквы.
Вступление
xVASynth (или [SK]VASynth, для голосов Skyrim) — это приложение с искусственным интеллектом, которое генерирует реплики озвучки, используя определенные голоса из видеоигр. Он может преобразовывать текст в речь (TTS) из текстового ввода или речь в речь (S2S) из аудиовхода. Приложение использует модели FastPitch [1,2], которые дают пользователям художественный контроль над высотой тона, длительностью и значениями энергии (только модели v2+) для каждой буквы в аудио. Они также позволяют генерировать звук с явно заданным произношением через нотацию ARPAbet.
Использование нейронного синтеза речи приводит к естественному звучанию голоса, что очень сложно сделать с помощью более традиционных методов, включающих объединение существующих данных. Это также означает, что может быть сгенерирован новый словарный запас помимо того, что актеры озвучивания уже прочитали.
Корисні посилання: