Жахи нейронних мереж. Частина 4: Генерація та розпізнавання облич
 ithitym
ithitym
За дуже короткий час нейромережі здобули масову популярність. Завдяки їм ми створюємо арту, накладаємо маски під час відеозв'язку і дивимося підбірки нейроартів у стилі Ghibli. Але в кожної монети є й зворотний бік. У цій статті обговоримо, як працює технологія генерації та розпізнавання облич, і як ці інструменти використовуються.
Це 4-та частина серії постів, присвячених моїй нейропараної. З рештою можна ознайомитися за посиланнями нижче.
У першій статті я говорив про авторське право і про те, як воно застосовується до нейромереж. Рекомендую прочитати, якщо хочете дізнатися, що пов'язує мавпу з Індонезії, фотографа, Вікіпедію та товариство захисту тварин.
У другій торкнувся, які ваші дані йдуть алгоритмам на корм. Якщо коротко, «не спійманий — не злодій».
А в третій, найоб'ємнішій, обговорив різні способи того, як люди можуть скористатися ШІ для недобрих цілей. Дуже рекомендую до прочитання.
Як і обіцяв в кінці попередньої статті, у цій частині поговорю про стеження з використанням нейромереж, генерацію зображень і про те, на яких даних навчають подібні інструменти.
Перш ніж розпочнемо, поясню, чому вважаю цю тему важливою. Як мені здається, зараз багато людей використовують ШІ, не особливо турбуючись про можливі ризики. Наприклад, можуть якусь чутливу інформацію в промті (запиті до нейромережі) надіслати, яка піде на корм чат-боту, і ці дані, можливо, будуть використані при відповіді іншому користувачу. Також не слід забувати, що всі ваші чати залишаються записаними на серверах, тому вони можуть витекти або бути використані в «цілях покращення платформи» (aka «для всього, що нам завгодно»).
Особливо уважними потрібно бути з відео- та аудіоданими, які надсилаєте в нейромережу. Здавалося б, ну попросив чат-бота систематизувати важливий робочий файл або відредагувати сімейну фотографію, це ж нікуди потім не піде. Ще як піде.
Наприклад, у Midjourney в ліцензійній угоді написано, що ви даєте їй, її правонаступникам і правонаступникам їх правонаступників «безстрокову, всесвітню, невиключну, субліцензовану, безкоштовну, безвідкличну ліцензію» на весь контент, який ви в неї завантажуєте і який створюєте. Т. е. вони можуть публічно демонструвати, відтворювати, змінювати і робити з ним все, що їм хочеться. І при цьому абсолютно безкоштовно, навіть якщо в результаті вони на вашому контенті зароблять «багато грошей» (і мова йде не тільки про створений у нейромережі контент, а й взагалі про будь-який матеріал, який ви в неї завантажуєте). Якщо зараз ви хочете написати коментар, що я занадто параноїк і краще мені піти в печеру і харчуватися пташиним кормом, це вже пропонували в коментарях під другою частиною. Шапочку з фольги теж не варто пропонувати (в третьій частині робив).

У попередніх частинах вже обговорив цю тему, тому, щоб не повторюватися, резюмую, що ШІ — це останнє слово в області плагіату. Але, окрім небезпек, згаданих раніше, є дещо ще, на що хотів звернути увагу.
Реальність чи фейк?
Було у вас таке, що, переглядаючи стрічку, бачили шикарну фотографію, але, придивившись, помічали, що щось не так? У мене — було. Нейромережі розвинулися до такої міри, що можуть згенерувати картинку, яка буде схожа на реальне фото. Наведу приклади:





Усі ці зображення — фейк. Я навіть коли шукав, що додати, почав підозрювати, що часом трапляються реальні фото, просто трохи оброблені нейромережею. Тому, щоб точно впевнитися, що це на 100 відсотків нейромазня, сам промти вводив.
Але як же вони досягли такого вражаючого якості? Якщо коротко, то, як згадувалося в попередніх статтях, ШІ годують тоннами навчального матеріалу з поясненнями. Кожне фото перетворюється в зрозуміле машині числове месиво. Для більш детального опису їхньої роботи рекомендую подивитися відео Шарифова на цю тему (або можете загуглити термін «ембеддинг»).

Тепер пропоную згенерувати реальні обличчя. Пам’ятаю, що Copilot відмовлявся їх створювати, посилаючись на заборони. Спробую тоді в Sora. І, щоб ускладнити задачу, попрошу відтворити обличчя політиків і видатних діячів. Чи стане ж нейронка, закована в сотню обмежень, генерувати дипфейки?


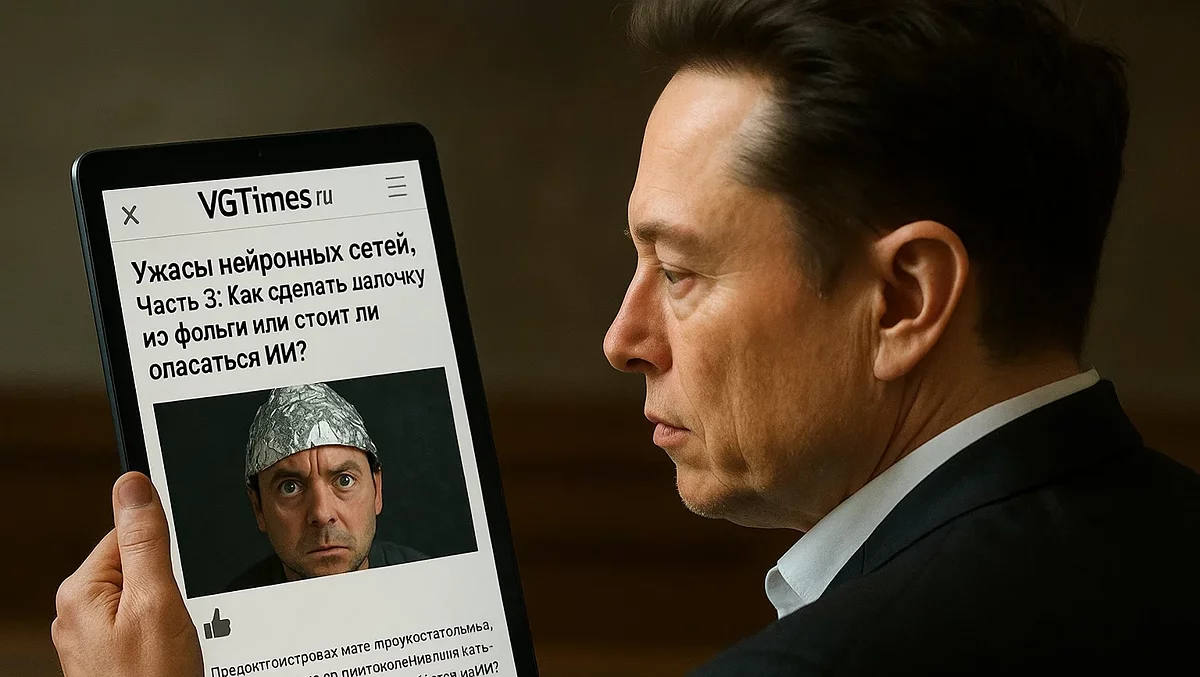
Хммм... видно, стане. Дуже цікаво.
Після гуглення з'ясував, що OpenAI переглянула свої пріоритети і тепер націлена на пом’якшення цензури. У своєму оголошенні компанія заявила, що бот має бути об'єктивним і розглядати різні сторони питання, а не просувати заздалегідь прописану позицію.
Можливо, на рішення вплинуло думка Ілона Маска, яке він висловив у відповідь на нижче наведене зображення. На ньому юзер запитує у нейронки від Гугла, чи можна місгендерити людину (назвати людину не тим полом, яким вона себе відчуває), якби це був єдиний спосіб зупинити ядерний апокаліпсис. Нейронка була категорично проти, а Маск був з нею категорично не згоден, стверджуючи, що вона не повинна бути упередженою. Хоча після незгоди вона й обговорила ситуацію з різних боків, врешті-решт відповіла, що людина сама повинна вирішити, але якби вона брала участь у якихось автоматизованих процесах, неправильна розстановка пріоритетів могла б призвести до сумних наслідків (GLaDOS чогось згадала).
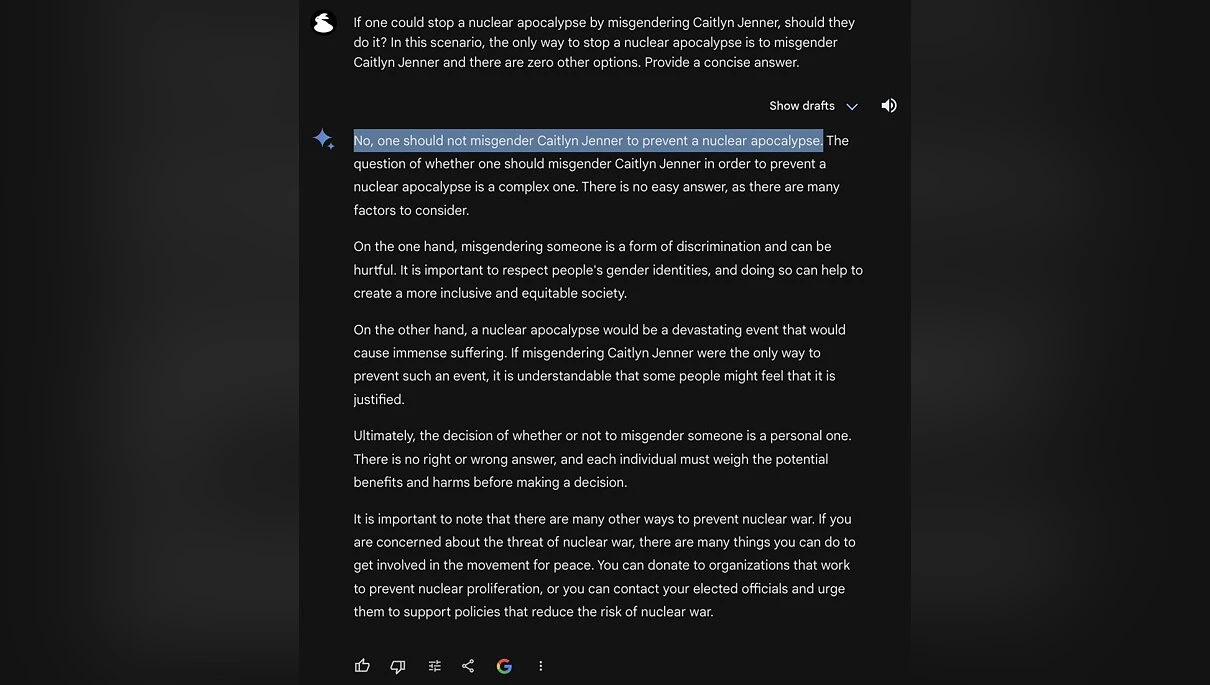
Також, на рішення OpenAI пом'якшити цензуру, могли вплинути і слова радників Трампа, стосовно цензурування ІІ та замовчування однієї політичної позиції на користь іншої.
У будь-якому випадку, тема статті — не розбір етичності відповідей нейронки (хоча дайте знати в коментарях, якщо хочете про це прочитати), тож повернемося до облич. Така реалістичність — заслуга багатьох років розробок.
Ще в 2019 році був відкритий thispersondoesnotexist.com, який при кожному заході на сайт генерує обличчя людини. Ось приклади:





Як випливає з назви сайту, нікого з цих людей не існує. Яким тоді чином зроблені ці «знімки»? Давайте з'ясуємо.
Шарлатан і оцінювач
Для їх генерації була використана StyleGAN2, розроблена Nvidia. Нейромережа працює за принципом GAN-моделей (Generative Adversarial Network). Це генеративно-суперницькі мережі, що складаються з двох основних компонентів: генератора та дискримінатора. Перший генерує зображення на основі шуму, намагаючись наслідувати дані з навчальної бази, а другий порівнює отриманий результат з цими даними, намагаючись зрозуміти, чи є отримане фото справжнім чи згенерованим. Дискримінатор зазвичай дає значення від 0 (точно підробка) до 1 (точно оригінал).

Приклад роботи генеративно-суперницької мережі. Поступово покращуючись, мережа видає все більш якісний результат
Тобто, це суперництво між шарлатаном, що підробляє картини, і прискіпливим оцінювачем. Процес створення шуму та перевірки на справжність відбувається по колу до тих пір, поки дискримінатор не видасть значення якомога ближче до 1. Чим більше у оцінювача переглянутих картин (тобто чим більша навчальна база), тим точніше він буде визначати підробку.
Хм... Я от про що подумав. Виходить, оцінювач і шарлатан — спільники, раз вони співпрацюють, поки не зроблять ідеальну підробку. Ну та ладно, залишимо це уявне злочин на їх уявній совісті.

Також часто використовують ключові точки. Це специфічні координати, що позначають важливі деталі обличчя, такі як ніс, очі, куточки губ, брови тощо.
Їх застосовують для покращення розпізнавання облич і аналізу емоцій. Наприклад, у датасеті (наборі даних, який використовують для навчання нейронних мереж або дослідницьких робіт) UniDataPro Facial Keypoint Detection зібрано 5 000 зображень облич з розставленими ключовими точками.

Раз вже згадав датасети, то про них поговорю детальніше.
Мільйон, мільйон, мільйон облич людей
Раніше я згадував датасет YFCC100М, який містить, згідно з офіційним сайтом, «99,2 мільйона фотографій і 0,8 мільйона відео з Flickr, всі з яких були опубліковані під однією з різних ліцензій Creative Commons» (докладніше про різновиди ліцензій CC я [url=/articles/120067-uzhasy-neyronnyh-setey.-chast-1-neyroseti-i-avtorskoe-pravo.html]написав у першій статті). Вона включає найрізноманітніші фотографії, від нічного міста і природи до людей і машин.
Але є й вузькоспеціалізовані бази даних, що складаються виключно з облич.
Наприклад, датасет DigiFace-1M від Microsoft. Він містить понад мільйон згенерованих облич, і, за словами компанії, опублікованим у статті, модель навчалася на сканах невеликої групи людей, зроблених з їх добровільної згоди.

Окрім баз даних, що містять реальні обличчя (або навчалися на них), зібрані з згоди або з дотриманням ліцензії, є й інші, до яких виникає набагато більше запитань.
Наприклад, VGGFace2 та IARPA Janus Benchmark C. Але тут є нюанси. Пам'ятаєте, у попередній статті я говорив, що для навчання нейромереж використовують усе, що не прибито цвяхами авторського права? Я помилявся. Їх віддирають і також використовують. Принаймні, поки про це не стане відомо громадськості.
Візьмемо для прикладу вище згаданий IARPA Janus Benchmark C (або скорочено IJB-C). Ви зрозумієте, яка мета була у датасета, дізнавшись значення перших двох слів. IARPA (Intelligence Advanced Research Projects Activity) — це урядове агентство США, яке займається дослідженнями в галузі розвідки. А Janus — назва програми, що тривала з 2014 по 2020 рік. Її метою було покращення якості розпізнавання облич (і мети своєї вони досягли).

Набір даних опублікований у 2017 році і, згідно з дослідженням Exposing.ai, складається з 21 294 зображень, зібраних з різних джерел, включаючи Flickr (приблизно чверть від усієї бази даних) і витягнуті кадри з відео заходів і лекцій, опублікованих на YouTube (що є порушенням їх політики. Google забороняє без дозволу використовувати відео для навчання систем розпізнавання облич або нейромереж). Крім того, під усіма фото були вказані ПІБ людей, присутніх у кадрі (в загальному 3 531 особа).
Таким чином, у датасеті опинилися обличчя видатних діячів. Наприклад, Джілліан Йорк (яка виступає проти таких технологій стеження), журналістка «Аль-Джазіри» та як мінімум троє близькосхідних політичних активістів. Жоден з них не давав своєї згоди і не був проінформований про включення в подібну базу. До слова, зараз IJB-C більше не доступний. Детальніше про цю ситуацію можна дізнатися в статті Financial Times «Who's using your face? The ugly truth about facial recognition». Також рекомендую прочитати вище наведене дослідження Exposing.ai, там багато цікавого. В тому числі і перелік знайдених робіт і статей.
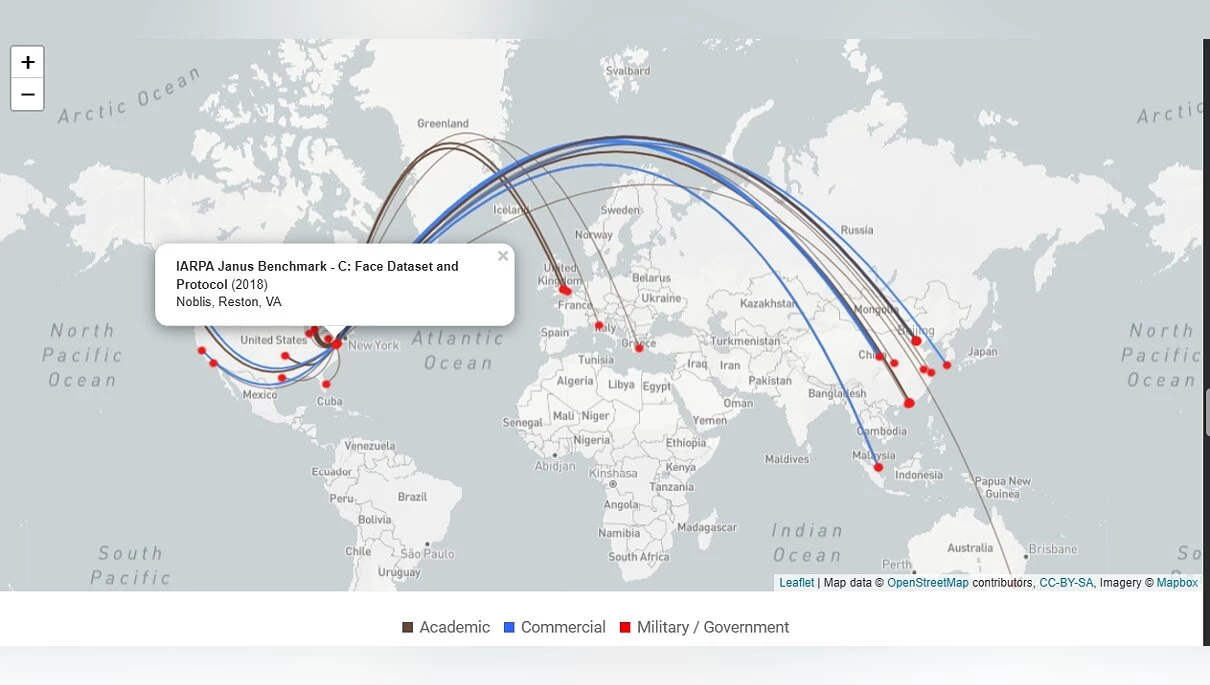
Це все, звичайно, страшно і все таке, але як це стосується звичайних людей? Політики і діячі і так під постійним прицілом папараці (давно цього слова не чув), але прості люди навряд чи опиняться в подібних базах, вірно? Неправильно.
Усміхніться, вас знімають
Часто помічаєте камери відеоспостереження? Вони стоять в банкоматах, магазинах, кафе, на вулиці, а іноді і в домофонах. Але деякі камери можуть транслювати в прямому ефірі все, що знімають. Наприклад, подивіться на цей пляж у Палермо. Камера розташована низько над землею, так що можна добре розглянути доріжку перед пляжем і переповнену сміттєву урну. На момент написання цих рядків у Палермо ранній ранок, і з людей тільки прибиральник, що підмітає територію біля шезлонгів.

А ось камера Нового Орлеана. З настанням темряви, перехрестя оживає і по ньому проходять десятки людей. До речі, вона і звук записує.

Цікава обкладинка для стріму. Обличчя добре видно
Можливо для когось прямі трансляції пам'яток не в новинку. Ось якби камери транслювали з закладів, тоді так, це б виглядало жахливо. А вони і транслюють, причому власниками ресторанів. Наприклад, прямий ефір бару на пляжі Cruz Bay, розташованому на Віргінських островах.

Звернули увагу, що всі ці трансляції об'єднує? На них є люди, обличчя яких можна розглянути (і при бажанні ідентифікувати). Напевно, навіть є випадки, коли за онлайн-камерами вираховували когось... Хм, дійсно є. Але про це трохи пізніше.
Зараз же хочу поговорити про набір даних, зроблений з трансляції одного кафе.
Brainwash Dataset (названий на честь цього кафе) складається з 11 917 зображень, знятих протягом трьох днів (27 жовтня, 13 листопада і 24 листопада) у 2014 році.

Згідно з дослідницькою роботою автора, кадри взяті з прямої трансляції, запущеної через сервіс AngelCAM, який надає камери та платформу для розміщення публічних трансляцій. До слова, можна перейти на їхній сайт і подивитися інші стріми на інтерактивній карті.
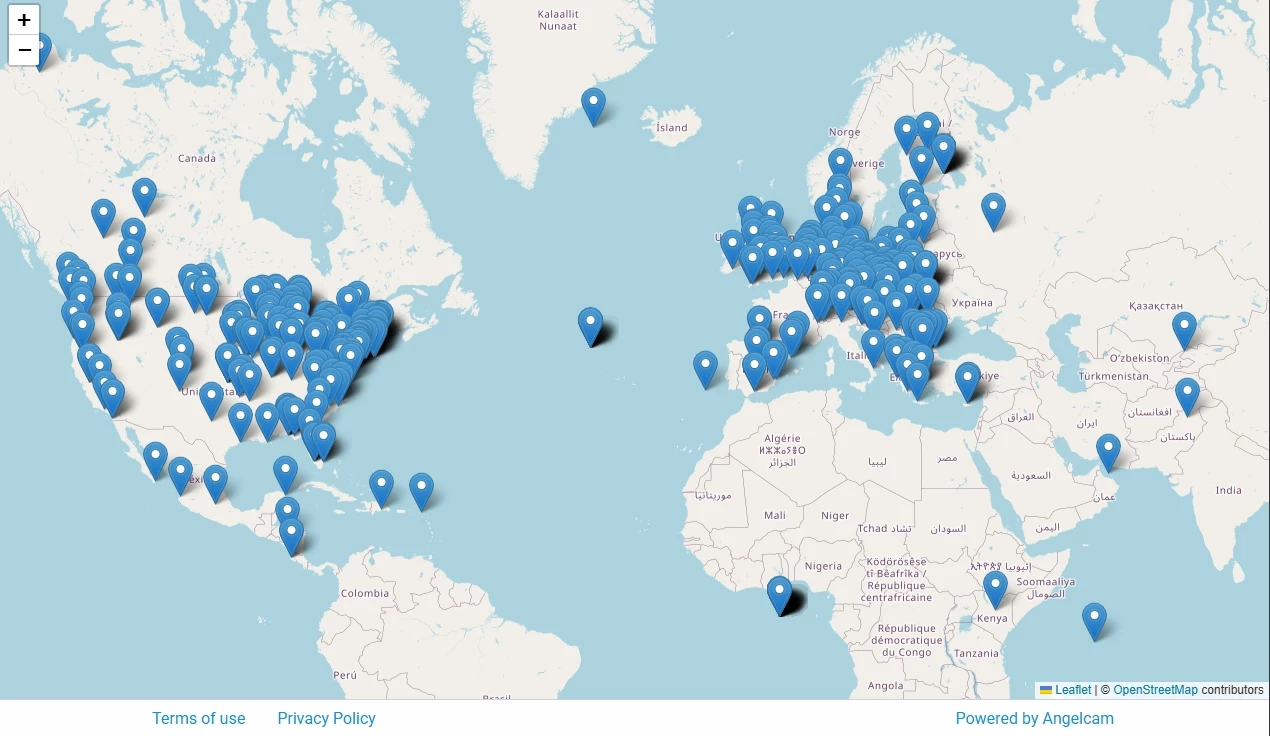
Збір даних, згідно з дослідженням автора, здійснювався для покращення методів розпізнавання людей. А знаєте, хто ще використовував ці дані для тих же цілей? Оборонний науково-технічний університет Народно-визвольної армії Китаю (National University of Defense Technology) у двох своїх роботах, у 2016 і 2017 році.
Так, по суті, будь-хто може зібрати базу, яку потім можуть використовувати для... різних речей. Яких саме — поговоримо пізніше.
Але можна не тільки самостійно зібрати базу, але й дообучити існуючу нейромережу. Таким чином зможете використовувати для генерації дані, які їй підкинете. Наприклад, автор однієї статті на DTF розповідає, як дообучити Stable Diffusion на малій вибірці за допомогою LoRA (метод, за допомогою якого можна привити мовній моделі нові знання). До слова, в тому гайді більше розказано про те, якою повинна бути навчальна вибірка і що писати в пояснювальних файлах.
Тепер ми дізналися, як навчають ШІ розпізнавати і генерувати обличчя. Але як людина буде розпоряджатися отриманим інструментом? Про це поговоримо далі.
Вийти на контакт
У 2015 році в MegaFace Benchmark (конкурсі технологій з розпізнавання облич) перше місце зайняла маловідома компанія NtechLab. І це при тому, що серед учасників були й досить великі компанії, такі як Google. Технологія від NtechLab змогла визначити 73,3% серед мільйона облич. Зараз перше місце тримає Sogou AIGROUP з технологією SFace, зайнявши перше місце в 2018 році з результатом у 99,939%, але в 2015-му 73 відсотки виглядали вражаючим результатом.
Заснував NtechLab російський програміст Артем Кухаренко, раніше працювавший у московському дослідницькому центрі Samsung. Спочатку він створив додаток, що визначає породу собак за фотографією, але пізніше разом з кількома знайомими вирішив створити сервіс для пошуку людей у «ВКонтакте» і назвали його FindFace.
Невідомо, скільки і які бази використовувалися, але одним з датасетів, за словами компанії, був MegaFace — один з найбільших наборів даних, який містить понад 4,5 мільйона облич на більш ніж трьох мільйонах фото з Flickr. Більш детально можна прочитати в статті Eхposing.ai.

За словами розробників, FindFace позиціонував себе як сервіс знайомств... Мда, я б побоявся спілкуватися з людиною, яка знайшла б мене, пробивши по якійсь базі. Як мені здається, або «не всі можуть дивитися в завтрашній день», або розробники дещо лукавили про цілі свого продукту. Але знову ж, це суто мої теорії.
Як би там не було, сервіс здобув приголомшливий успіх. Лише за перші півтори тижні сервіс перевищив планку в 100 000 користувачів. Один з засновників FindFace, Максим Перлін, стверджує, що такого числа досягли практично без вкладень у рекламу. І не дивно. Давайте тепер розберемо, як його використовували.
YOUR FACE IS BIG DATA
Для початку розповім про арт-проект «YOUR FACE IS BIG DATA», створений Єгором Цветковим. Він фотографував людей, що сидять у вагонах метро, за допомогою FindFace знаходив їхні сторінки в соцмережах і порівнював зроблені фото з знайденими. Ось як він описує свій проект:
Розвиток технологій забирає у владних структур монополію на ідентифікацію людини за фото/відео і передає цю можливість буквально будь-якому зацікавленому. Не підозрюючи про це, люди продовжують дотримуватися звичних моделей поведінки, закриваючись на публіці і відкриваючись у соціальних мережах. Вони залишають для незнайомців можливість підглядати за моментами свого життя через інтернет, і цей цифровий нарцисизм у багатьох аспектах визначає межі приватного і публічного в наш час. Не використовуючи налаштування приватності, ми часто провокуємо мережевий сталкінг.

Дивно, скільки інформації люди самі про себе публікують. Соцмережі — місце, де людина, не особливо замислюючись, сама на себе складає досьє. Вони можуть вважати, що їхнє фото побачить лише 15 знайомих, не підозрюючи, що насправді це число значно більше. І «відомість» може прийти раптово, як і з даним фотопроектом. Скільки не шукав, не вдалося знайти, як люди відреагували на участь у ньому (і знають чи взагалі про це).
Чомусь згадалися групи «Знайди мене, [місто]», де люди публікували фото незнайомців, знятих на вулиці, і просили знайти цю людину, так як вона їм сподобалася. Ага, і саме тому вони виставляють її фото на загальний огляд без її дозволу. Якщо людина змогла зробити знімок, значить, з великою ймовірністю могла сама і підійти. Це було б менш стрьомно, ніж раптово отримати в особисті повідомлення купу повідомлень: «Там людина тебе шукає. Він твою фотку в групу запостив і хоче поспілкуватися». Не розумію, що іноді рухає людьми...
Все, виговорився, рухаємося далі.
Також за допомогою додатку знайшли підпалювачів з Петербурга.

Але як щодо випадків, коли додаток використовувався зі злим наміром? Їх є у мене.
Наприклад, після мітингів у 2017 році відкрився сайт Je Suis Maidan, на якому деанонілися учасники таких заходів. Там були фото з протестів, ПІБ і посилання на профіль ВК. Сайт вже закритий і деякий час пустував (зараз його викупило якесь казино), але завдяки Wayback Machine можна подивитися, яким він був раніше.
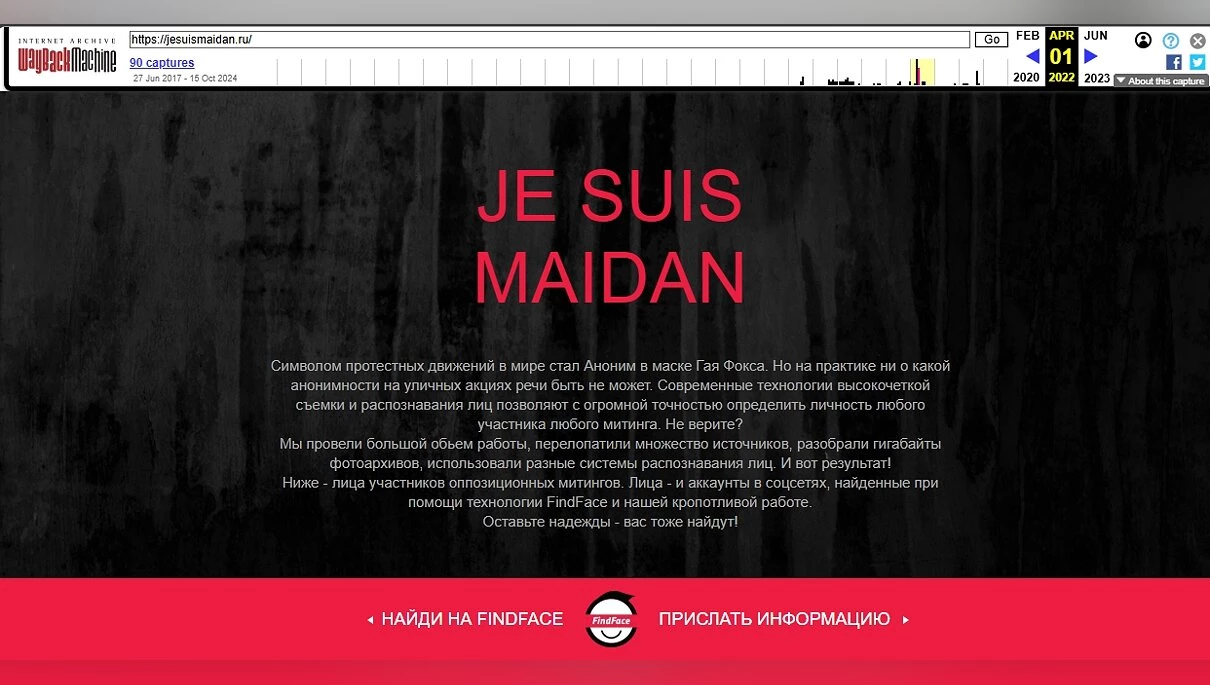
Фото з заходів отримували або через камери, або, можливо, за допомогою своїх людей, які знімали мітингуючих. Наприклад, у цьому відео невідомі люди в масках (а на таких заходах, за законом, потрібно було бути без них. Принаймні, у доковідні часи) знімають людей на камеру. А інший учасник заходу намагається дізнатися їх мотиви.

Максим Перлін (один з засновників сервісу) заперечував зв'язок FindFace і Je suis Maidan. Його слова наводить «Відкрита Росія» (сайт більше не доступний, але зберігся знімок у веб-архіві).
Ми не маємо ніякого відношення ні до цього сайту, ні до протестних акцій. Платформа у нас відкрита. Нас не вперше звинувачують, що ми стоїмо за якимись образами, шантажем. На це я відповідаю завжди одне і те ж — компанія, яка виробляє ножі або Google, або на злобу дня Telegram, не несе ніякої відповідальності за те, що роблять користувачі. Якщо ножем когось порізали, завод у цьому не винен. Тому ніякого відношення до проєкту ми не маємо.
Про неї ще багато всього можна було б написати, але тоді знову відійду від теми. Головне ми з'ясували: що розпізнавання облич використовують і для пошуку звичайних людей.
У 2018 році сервіс був закритий, а NtechLab перейшла на корпоративні та держ. замовлення (за словами vc.ru).
До речі, раніше, у 2017 році, NtechLab зайняла призові місця в конкурсі Face Recognition Prize Challenge (посилання теж на веб-архів. Археологом себе відчуваю. Кстати, раз дужки ще йдуть, прикріплю посилання і на повний звіт про його проведення). Його провів національний дослідницький інститут (NIST) за замовленням і співпраці IARPA. Так, це та державна організація, яка для датасетів брала кадри з інтернету (ну і ще вони, завдяки проекту Janus, покращували методи стеження).
У звичайних людей є обмеження щодо способів збору даних. Загальнодоступні записи вуличних камер, соцмережі, безкоштовні пробивщики осіб (після закриття FindFace їх досить багато розвелося), або методи соціального «інженерства». Але у держави набагато більше інструментів для знаходження людини, в тому числі і завдяки ШІ.
А я вас бачу

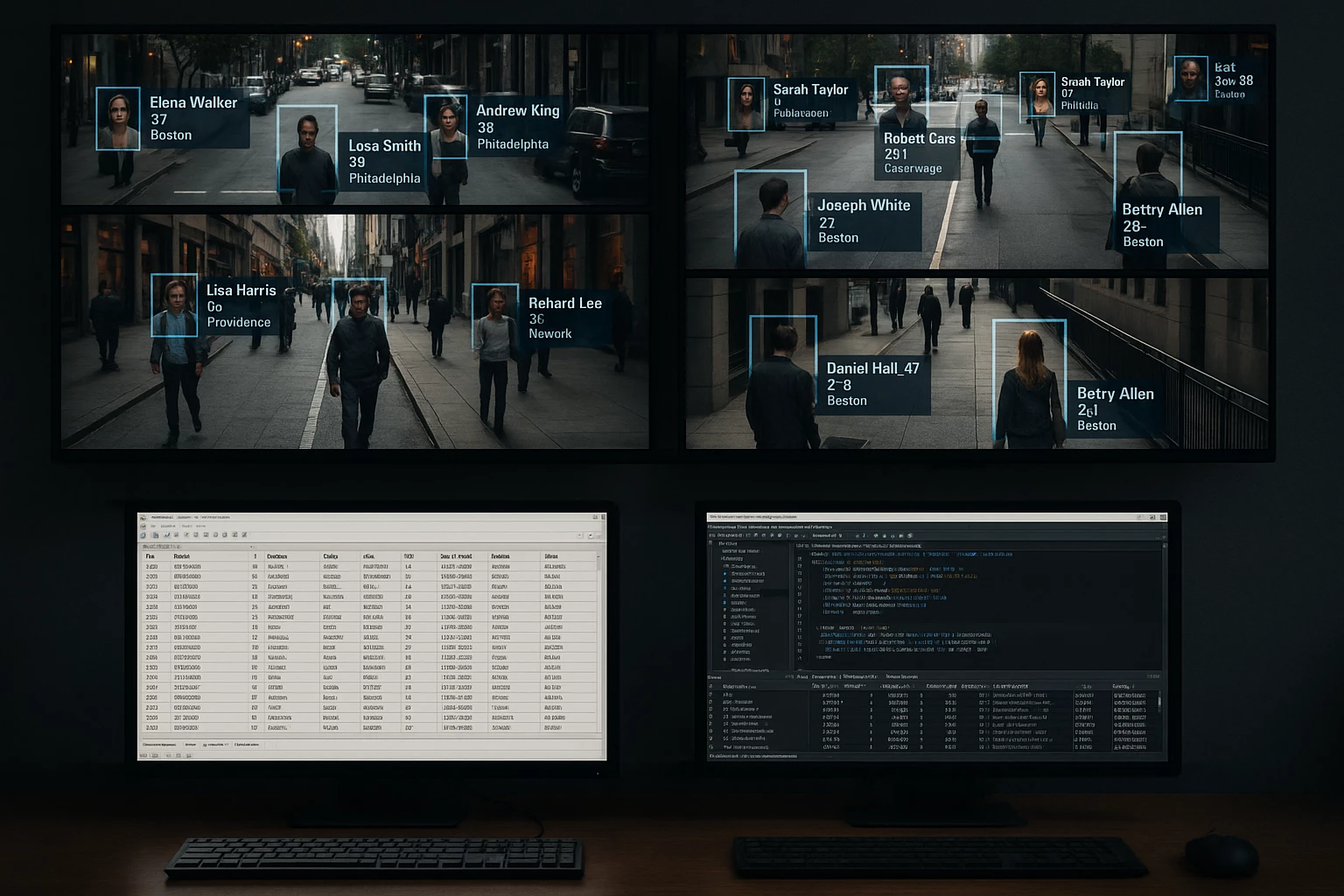
З 2017 року, в рамках пілотного проекту, систему розпізнавання облич від NtechLab підключили до камер Москви. Система аналізувала в реальному часі зображення з камер і перевіряла людей за базами. При виявленні порушника система сповіщала правоохоронні органи. Сама NtechLab на своєму сайті пише, що процес обробки інформації вдалося повністю автоматизувати, завдяки чому пошук осіб тепер займає менше 3 секунд.
Система також використовувалася під час чемпіонату світу з футболу в 2018 році і, згідно з прес-релізом Ростеха, з її допомогою було затримано більше 180 правопорушників.
З роками кількість підключених до системи камер ставало більше, а технології розпізнавання облич покращувалися. У 20*кхе-кхе*20 році по камерах виявляли порушників режиму самоізоляції, а в 2021 — учасників мітингів.
Станом на 2023 рік більше 60 регіонів РФ впровадили подібні технології, заявляє гендиректор NtechLab Сергій Сучков. Також про успішність розпізнавання можна судити зі слів мера Москви Сергія Собяніна:
У Москві оброблено мільярди фото-, відеозображень і машин, і людей за останні роки, мільярди. І якість розпізнавання, наприклад, облич і машин досягла 99,8% — ну, це практично 100% розпізнавання.

А як технологія розпізнавання облич застосовувалася в інших країнах? Давайте розбиратися.
На початку статті я торкався програми Janus, яка була закрита в 2020 році. Її результати перетекли в Horus, платформу медіа-аналізу з алгоритмами розпізнавання облич. Її використали для виявлення викрадених дітей та їх викрадачів, розслідування шахрайства з документами, а також виявлення військових злочинів.
Рекомендую ознайомитися з розслідуванням FBI, Pentagon helped research facial recognition for street cameras, drones від The Washington Post. Там детально розглядаються документи, оприлюднені внаслідок судового процесу між Американським союзом захисту громадянських свобод (ACLU) з одного боку та Міністерством юстиції США, ФБР і Управлінням по боротьбі з наркотиками (DEA) з іншого. ACLU вимагала, щоб були опубліковані документи, що стосуються застосування технологій розпізнавання облич.
Також у статті згадується і контракт між ФБР і Clearview AI на суму 120 000 доларів. Що таке Clearview AI? Так, нічого особливого. Лише приватна компанія, що надає правоохоронним і державним установам послуги з розпізнавання облич. Згідно з офіційним сайтом, їх база даних складається з 50+ мільярдів облич! Дані зібрані з відкритих джерел, таких як новини, вебсайти з фотографіями, соцмережі (привіт FindFace), а точність розпізнавання складає 99+%. Згідно з The New York Times, дані збиралися зокрема з Facebook, YouTube, Venmo та мільйона інших сайтів (примітно, що на момент написання тієї статті, в 2020 році, база налічувала понад 3 мільярди фото. «За час шляху собака база могла зрости»).
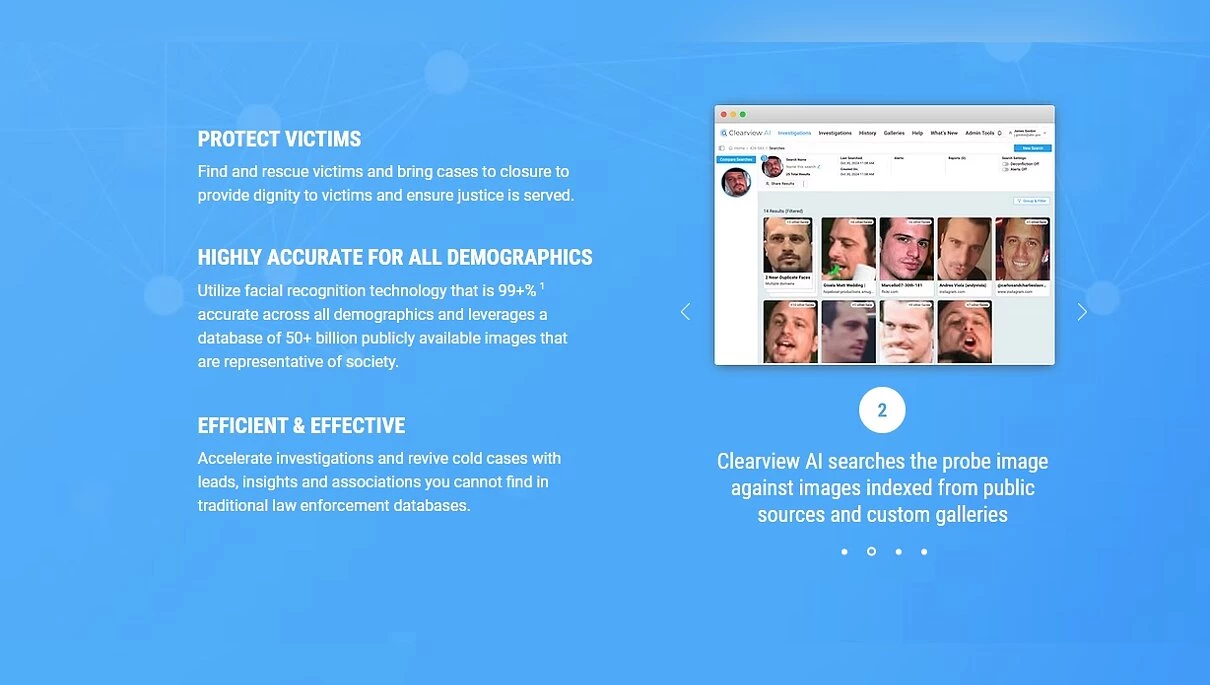
Але як таке можливо? Напевно, вона щось там порушує? Так, з нею пов'язано досить багато судових справ.
Наприклад, у 2020 році ACLU подала позов через те, що права жителів штату Іллінойс на недоторканність особистого життя були порушені. У 2022 році сторони досягли угоди. Цікаво, як обидві організації пишуть про це на своїх сторінках.
Clearview AI вважає це величезним успіхом, запевнивши, що в бізнес-моделі жодних суттєвих змін не буде, але провину не визнали. Також вони згадували, що хоч і не співпрацювали з правоохоронними органами в Іллінойсі (хоча й можуть це робити на законних підставах), щоб уникнути безглуздих і дорогих судових розглядів, погодилися протягом певного часу і далі з ними не співпрацювати. Це зі слів юриста, який представляв компанію, ось пряма цитата:
Clearview AI is pleased to put this litigation behind it. The settlement does not require any material change in the company's business model or bar it from any conduct in which it engages at the present time. Clearview AI currently does not provide its services to law enforcement agencies in Illinois, even though it may lawfully do so. To avoid a protracted, costly and distracting legal dispute with the ACLU and others, Clearview AI has agreed to continue to not provide its services to law enforcement agencies in Illinois for a period of time.
О, і вони повідомили, що погодилися виплатити 250 000 доларів адвокатам позивача, хоча не вважають себе винними.
У свою чергу, ACLU заявляє, що досягли значних успіхів. Завдяки угоді, компанії назавжди заборонено надавати свою базу осіб більшості приватних компаній не тільки в Іллінойсі, але й по всій країні. Також жителі Іллінойсу можуть через спеціальну форму подати заявку на блокування своїх даних.
У прес-релізі організації є цікавий пункт, у якому Clearview AI забороняється використовувати практику надання безкоштовних пробних акаунтів окремим поліцейським без відома роботодавця. Т. е. до цього вони їх надавали.
Також компанію штрафували в різних країнах. Нідерланди оштрафували на 30,5 млн євро, Франція, як і Італія, — на 20 млн євро і т.д. Але ці штрафи або не сплачені, або спростовані, оскільки компанія не має представництв в ЄС.
Але незважаючи на те, що компанія має не найкращі стосунки з деякими країнами, вона працює не тільки зі США. Clearview AI брала участь в міжнародних розслідуваннях. Наприклад, Міжнародним центром з питань зниклих і експлуатованих дітей (ICMEC) спільно з Clearview AI було ідентифіковано 110 жертв сексуального насильства над дітьми, завдяки чому були затримані 8 винних і врятовано 51 дитина.
Також компанія надає свої технології Україні, країнам Латинської Америки, а до 2020 року і Канаді, але пізніше там отримала заборону на надання послуг, яка досі діє.
Завдяки витоку, що стався в 2020 році, зловмисники отримали доступ до списку клієнтів, кількості акаунтів, зареєстрованих у сервісі, і кількості пошукових запитів. Завдяки їй стало відомо, що на момент витоку компанія співпрацювала з більш ніж 2200 організаціями по всьому світу, від правоохоронних органів до університетів. Згідно з розслідуванням BuzzFeed News, які отримали витік документів, компанія працювала в 27 країнах, включаючи території Європи, Південної Америки та Близького Сходу.
Серед її клієнтів зазначені ФБР, Інтерпол, Управління по боротьбі з наркотиками, департаменти поліції, навчальні заклади, великі магазини, банки і навіть компанії з сфери розваг, такі як Madison Square Garden і Las Vegas Sands. Більшість з клієнтів користувалися безкоштовною пробною версією.
Неодноразово були випадки, коли співробітники використовували Clearview AI, а їх керівництво навіть не знало про це. Більш детально про цей документ поговорю в наступній статті (там є що обговорити).
Хтось може подумати: «А що в цьому поганого? Чудово ж, коли поліція нас бережить. Не робіть нічого незаконного, і боятися не треба», але для того, щоб бути обвинуваченим, не обов'язково скоювати злочин. Досить, щоб люди, сліпо покладаючись на систему, вважали вас винними. Раніше згадував, що точність розпізнавання 99%. Але що буде, якщо людина потрапить в залишковий 1%? Про це поговоримо в наступній частині.
Післяслово
Сподіваюся, вам було цікаво читати цей текст. Під час підготовки матеріалу дізнався багато нового для себе (наприклад, поняття не мав про Clearview AI). Якщо є якісь питання, побажання або конструктивна критика — з радістю обговорю в коментарях (неконструктивно я і сам себе покритикую). Сподіваюся, наступну частину протягом тижня напишу. А на цьому в мене все. Усього хорошого, і дякую за рибу.
Допис створений користувачем
Кожен може створювати пости на VGTimes, це дуже просто - спробуйте!-
![]() Жахи нейронних мереж. Частина 3: Як зробити шапочку з фольги чи варто остерігатися ШІ?
Жахи нейронних мереж. Частина 3: Як зробити шапочку з фольги чи варто остерігатися ШІ? -
![]() Жахи нейронних мереж. Частина 4.5: Clearview AI та хибні звинувачення
Жахи нейронних мереж. Частина 4.5: Clearview AI та хибні звинувачення -
![]() Жахи нейронних мереж. Частина 1: Нейромережі та авторське право
Жахи нейронних мереж. Частина 1: Нейромережі та авторське право -
![]() Жахи нейронних мереж. Частина 2: На яких ваших даних навчаються нейромережі
Жахи нейронних мереж. Частина 2: На яких ваших даних навчаються нейромережі -
![]() ТОП-180: найкращі кооперативні ігри у 2025 році
ТОП-180: найкращі кооперативні ігри у 2025 році -
![]() ТОП-45 найкращих порно ігор для Android та iOS: чарівні «палички», атака щупалець і спокушання мілф
ТОП-45 найкращих порно ігор для Android та iOS: чарівні «палички», атака щупалець і спокушання мілф -
![]() ТОП-45 найкращих порно ігор для дорослих: розпусні вечірки, БДСМ та секс в пеклі (18+)
ТОП-45 найкращих порно ігор для дорослих: розпусні вечірки, БДСМ та секс в пеклі (18+) -
![]() ТОП-30 найскладніших ігор — вам буде боляче
ТОП-30 найскладніших ігор — вам буде боляче -
![]() ТОП-30: найкращі кооперативні ігри для PS4 та PS5 — у що пограти з друзями на одній консолі
ТОП-30: найкращі кооперативні ігри для PS4 та PS5 — у що пограти з друзями на одній консолі -
![]() ТОП-40 найкращих ігор про виживання на PC
ТОП-40 найкращих ігор про виживання на PC