
Жахи нейронних мереж. Частина 7: Історія нейросетевої генерації мови. Частина 1: Від співаючого IBM до балакучої Аліси
 ithitym
ithitym
С синтезом мови пов'язано дуже багато злочинних схем: від клонування голосу до створення повністю фейкової особистості. Але перш ніж перейти до розбору шкоди, потрібно зрозуміти, як цей синтез влаштований. У цій частині поговоримо про перші розробки в галузі нейромережевого синтезу та про те, як ці технології вдосконалювалися.
Якщо ви вперше бачите цю серію статей і здивувалися цифрі 7 у назві, то я вас вітаю! У вас попереду кілька годин захоплюючого читання, що стосується різних аспектів нейромереж: від юридичних тонкощів авторських прав і випадків помилкових звинувачень на основі результатів ШІ до історії роботи вокалоїдів і посібника застереження про методи доксингу за допомогою чат-ботів. Це і багато іншого ви можете прочитати в попередніх частинах.
Усі «Жахи нейронних мереж»
- Жахи нейронних мереж. Частина 1: Нейромережі та авторське право
- Жахи нейронних мереж. Частина 2: На яких ваших даних навчаються нейромережі
- Жахи нейронних мереж. Частина 3: Як зробити шапочку з фольги чи варто остерігатися ШІ?
- Жахи нейронних мереж. Частина 4: Генерація та розпізнавання облич
- Жахи нейронних мереж. Частина 4.5: Clearview AI та хибні звинувачення
- Жахи нейронних мереж. Частина 5: Розпізнавання мови
- Жахи нейронних мереж. Частина 6: Типи синтезу мови. Від Стівена Гокінга до Хацуні Міку
- Жахи нейронних мереж. Частина 7: Історія нейросетевої генерації мови. Частина 1: Від співаючого IBM до балакучої Аліси
Отже, як вже зрозуміли з назви, мова піде про нейромережевий синтез мови. Його ми чуємо часто: озвучка донатів у стримерів, зачитування коментарів у блогерів або переказ фільму в Тік-Ток. Але як розвивався синтез і яким чином він працює?
Щоб одночасно нагадати, про що ми раніше говорили, і зв'язати цю статтю з попередньою, пропоную подивитися короткий ШІ-переказ, який накидав у NotebookLM. До речі, досить цікава річ, рекомендую ознайомитися.

Монтаж, слайди та озвучка — все зроблено в нейромережі
Весь ролик був згенерований всього одним коротким промтом (і посиланням на попередню статтю як джерело). Зверніть увагу на якість синтезованого голосу та його широкий спектр інтонацій. Чутно навіть, як диктор набирає повітря перед початком речення. Вражаюча якість! Але як же його досягли? Для цього треба згадати, з чого все починалося.
60-ті: Daisy, Daisy
Ще до зародження машинного навчання, у далекому 1961 році, у Bell Labs кипіла робота. Там проводилися дослідження в галузі синтезу мови, і вчені ламали голову над дивною на перший погляд задачею: як змусити громіздкий механізм під назвою IBM 7094 — співати. В результаті у них вийшло. Машина заспівала стару пісню 1892 року, яку ви, можливо, навіть нещодавно чули:
Daisy, Daisy,
Give me your answer, do!
I'm half crazy,
All for the love of you!
It won't be a stylish marriage,
I can't afford a carriage,
But you'll look sweet upon the seat
Of a bicycle built for two!

Композиція «Daisy Bell (Bicycle Built for Two)» стала першою в історії піснею, яку заспівав комп'ютер. Событие було настільки значущим, що цей факт увійшов у Книгу рекордів Гіннеса (правда, на їхньому сайті стоїть дата на рік раніше і пристрій IBM 704), а сама композиція увійшла в Національний реєстр аудіозаписів Бібліотеки Конгресу (а от тут вже значиться 1961. Кому вірити — незрозуміло).
Запис стала культовою. Її ви могли почути в Космічній Одіссеї Стенлі Кубрика або ж у недавній серії Дивовижного Цифрового Цирку. Навіть голосові помічники такі як Alexa і Cortana могли зробити на неї посилання. Але яка проривна технологія стояла за цим рекордом? Зараз поясню.

В той час про нейронний синтез навіть мови не йшло, так що викручувалися як могли. Для синтезу звуку використовувалася модель голосового тракту, що отримала назву Kelly-Lochbaum Vocal Tract Model на честь її винахідників. Ця модель базувалася на з'єднаних трубках з циліндричними порожнинами. Звук, проходячи через циліндри, відбивався і змінював своє звучання. Більш детально ви можете прочитати в цій статті, але якщо дуже грубо узагальнити, це як формантний синтез, але з трубками замість формантних фільтрів. На вході подається звук, який, проходячи через серію трубок з різними порожнинами, змінює звучання. Ось як це виглядає на практиці.

Тільки з маленьким таким відмінністю. Трубки були цифровими. Вся модель була програмно змодельована на основі фізичних принципів. Для тих, хто хоче ознайомитися з моделлю роботи ближче, залишаю посилання на статтю Стенфордського університету.
Але така система синтезу не отримала подальшого розвитку, поступившись більш практичним методам.
80-ті — 90-ті: зародження нейромереж і NETtalk
Ранні спроби нейронного синтезу голосу були ще в 90-х. Мова не йшла про повний синтез. Машинне навчання застосовувалося в окремих компонентах. Наприклад, для написання фонетичної транскрипції тексту. Ця нейромережа називалася NETtalk. Вона складалася з кількох частин: на вхід надходив масив інформації, який, проходячи через приховані шари нейронів, розбиралося на зрозумілі системі математичні розрахунки. І в підсумку, на основі нейронів, навчених на попередньому кроці, система генерувала вихідні дані. Це дуже спрощений принцип роботи нейромереж, трохи нижче його доповню, але якщо візуалізувати, вийде така схема:
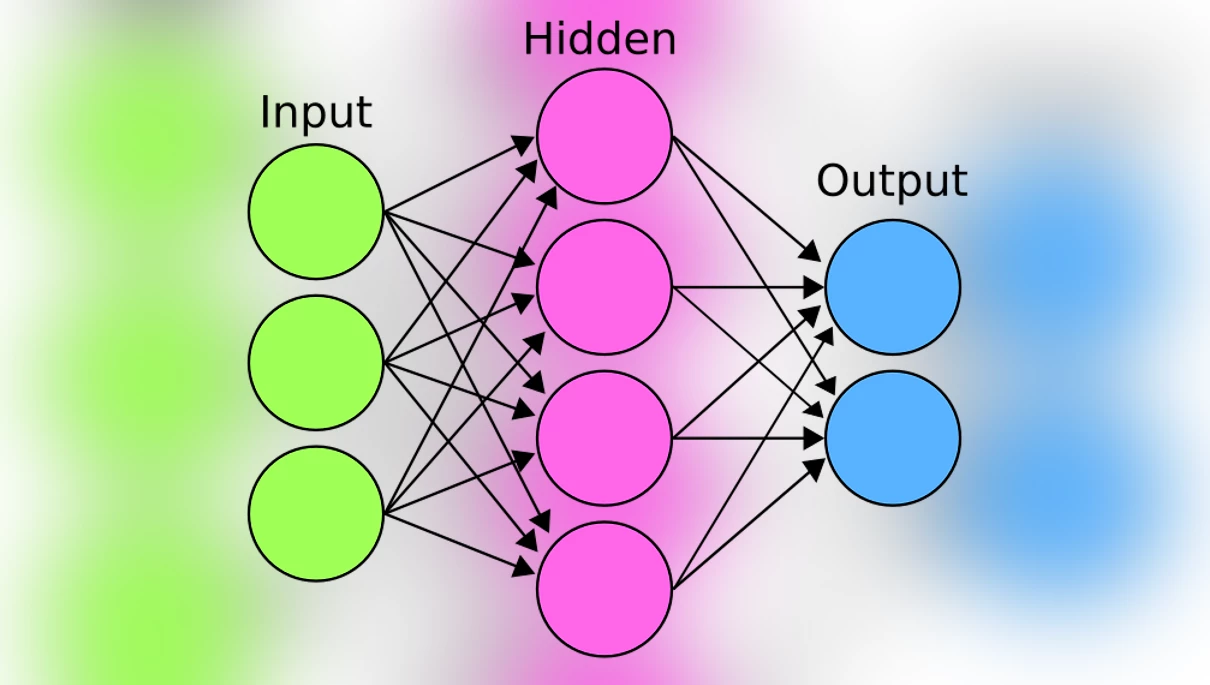
На вхід NetTalk подавалися англійські слова, які надходили в прихований шар з нейронів. (Слід зазначити, що це була примітивна нейронна мережа, що складалася з єдиного шару з 80 прихованих нейронів.) У цьому шарі відбувалися обчислення, завдяки яким на виході генерувалася фонетична транскрипція, яку синтезатор міг озвучити.
І на той час результат був цілком собі непоганим.

Щось подібне проводили дослідники з Motorola, описавши процес у роботі Speech Synthesis with Neural Networks. Їхній метод синтезу базувався на time-delay neural network (TDNN). Вона також готувала дані для озвучування, і її структура була схожа на NetTalk, але на відміну від неї враховувала контекст, тобто попередній результат операції, для кращої якості видачі. Система складалася з двох основних нейромереж, налаштованих під певні завдання. Принцип дії був таким: на вхід подавали текст, який перша нейромережа перетворювала на фонетичне та акустичне представлення.
Далі друга нейромережа розраховувала тривалість для кожної окремої фонеми.
Результати перших двох кроків складалися в остаточний акустичний опис кадру (уривка тривалістю в 10мс).
Дані передавалися на вокодер, спеціальний компонент, що перетворює дані в звуковий сигнал. Вокодер не був нейронним, оскільки інакше це забирало б занадто багато ресурсів.
Але нейромережеве дерево зі схованими шарами не є єдиним, що об'єднує систему, створену 30 років тому, з сучасними моделями. У них також спільний принцип навчання, заснований на системі зворотного розповсюдження помилки (backpropagation). Не лякайтеся цього терміна, принцип його роботи досить цікавий і захоплюючий.
Щоб було зрозуміліше, уявіть собі контрольну з математики. Ви довго думаєте, але не дуже розумієте, як її вирішити. А від результатів залежить ваша підсумкова оцінка, тому щось написати потрібно. Тому з горем навпіл розписуєте задачу і приходите до якогось відповіді, в якому не дуже впевнені. Тут ви краєм ока, абсолютно випадково, у відмінника за сусідньою партою помічаєте відкритий зошит. Встигаєте побачити тільки кінцевий результат обчислень, але він, помітивши ваш пильний погляд, закриває зошит. Ви записуєте підглянутий результат і починаєте думати над тим, яким чином цей скупий чоловік прийшов до таких висновків. Тобто ви, знаючи правильну відповідь, аналізуєте, де допустили помилку в розрахунках, щоб у подальшому розуміти, як вирішувати подібні задачі.

Те ж саме стосується і нейромереж. Спочатку їм подають масив даних, який перетравлюється на патерни і перетворюється на ваги та зсуви в нейронах.
Але щоб зрозуміти, наскільки правильно нейромережа засвоїла матеріал, на виході дається зразок, який машина порівнює зі своїм результатом і проганяє через ваги в зворотному напрямку, коригуючи свої шестерні, щоб спотворень було менше. І таким чином нейромережа переглядає мільйони зразків, прагнучи зменшити функцію втрат (числове позначення серйозності помилки). До слова, в великих мовних моделях цю функцію практично неможливо звести до нуля, але про це поговоримо в наступний раз, коли доберемося до пояснення галюцинацій. Повертаємося до наших баранів, нейронів.
Якщо хочете розібратися самостійно в принципі роботи, прикріплюю хороше пояснення від 3Blue1Brown.

На той момент у цього методу був величезний мінус, пов'язаний із затуханням сигналу. Якщо у нейромережі було більше певної кількості шарів, то сигнал не доходив до початку і затухав (як енергетичний шар з Portal). Для збереження сигналу були розроблені кілька рішень (наприклад, ReLU або LSTM), але до їх практичного застосування в нейронному синтезі залишалося ще чимало часу. Тому поки поговоримо про інший тип синтезу, який використовувався до епохи нейромереж.
2000-і: Цепи Маркова
Технології не стояли на місці, і вже в 00-х з'явилися мережі, що працюють на основі ланцюгів Маркова, а точніше, на прихованій марківській моделі (hidden Markov model, скор. HMM). Марківські ланцюги лягли в основу багатьох повсякденних речей, наприклад, завдяки їм пошуковик знаходить потрібний сайт, а телефон розуміє, яке слово хочете написати. Тема її реалізації дуже цікава, але, щоб не заглиблюватися у всі ці мудровані речі, рекомендую подивитися цікавий ролик Veritasium (особливо якщо хочете дізнатися, як пов'язані задетое его російського академіка, «Євгеній Онегін», ядерна бомба і Google).

HMM використовували значні компанії того часу, серед яких: Toshiba, Microsoft і Google. Але звернути увагу хотів на проект Festival від The Centre for Speech Technology Research (CSTR), що надає безкоштовну систему синтезу мови для Linux (але можна і під Windows запустити). Остання версія програми з 2017 року включає в себе більше 15 англійських голосів. Зараз, на жаль, сайт виглядає покинутим, але досі доступна документація та посилання на проект. Серед вбудованих голосів є й ті, які засновані на HTS (Hidden Markov Model-based Text-to-Speech), ось приклад звучання.

До слова, можна самим створювати голос для Festival, за допомогою допоміжної програми FestVox і детальної навчальної документації до неї.
Цікавий факт: У попередній частині я розповідав про RHVoise, безкоштовну TTS систему, яку робить сліпий програміст разом із спільнотою. Так от, в основі механізмів її роботи також лежить HTS. Ось що про це говориться на Хабрі:
У своїй роботі синтезатор використовує статистичний параметричний синтез і був заснований на напрацюваннях вже існуючих проектів, таких як HTS, і опублікованих наукових дослідженнях. Це гібридна глибока нейронна мережа, що працює зі схованою марківською моделлю. Завдання таких мереж — це розгадка невідомих параметрів на основі спостережуваних. Можна вважати, що це найпростіша Байєсівська мережа. Сам HTS був заснований на напрацюваннях іншого проекту — HTK. Але нас тут найбільше цікавить, що частина напрацювань була опублікована для вільного використання, включаючи опис алгоритмів і застосованих технік.
Все ж таки круто, що деякі люди свідомо публікують свої роботи, щоб внести вклад в загальнолюдське благо. Але я знову відволікся, рухаємося далі.
На схованих марківських моделях працював і синтез мови в сервісі Yandex SpeechKit, який надавав послуги з розпізнавання та синтезу мови як на платній, так і на безкоштовній основі. Налаштування можна подивитися в цьому імпровізованому голосовому стендапі (який озвучений сворою інших Text-to-speech голосів).

До слова, таке якість було у тодішніх TTS-систем, заснованих на параметричному та конкатенативному синтезі. Серед них ви, напевно, помітили дуже запам'ятовуваний чоловічий голос. Це легендарний Ivona Maxim, який використовувався в продуктах Amazon (наприклад, в Amazon Kindle). У свій час він був дуже популярний і використовувався для озвучення донатів, зачитування тексту або в телепередачах. Наприклад, у виступах Прозорого Гонщика, типу цього:

Бот Максим, як його звикли називати в народі, працює на основі конкатенативного синтезу, а заснований на голосі Сергія Костилєва — акторові дубляжу, який був диктором каналу Discovery. Якщо хочете поекспериментувати з голосами, можете озвучити ними будь-який текст на сайті, що надає TTS системи. Ну а ми рухаємося далі.
2013 — Глибокі дослідження в області Deep Neural Network

З 2013 року почалися активні дослідження в області нейронного синтезу мови. Вони поклали початок майбутнім відкриттям і комерційним продуктам. До цього часу для синтезу мови використовували переважно інші, більш звичні підходи.
З 2013 по 2015 виходили різні дослідження та статті на тему нейромереж. Наприклад, дослідники з Google і Microsoft, прийшли до висновку, що нейромережевий підхід перевершує HMM метод. Але слід розуміти, що з моменту досліджень до їх впровадження в комерційні продукти, зазвичай необхідно тривале час, тому наступний етап розвитку настав через пару років.
2016-2017: Початок нової ери

Наступний стрибок відбувся в 2016-2017 роках. Ці роки були досить значущими для нейронних мереж і синтезу мови зокрема, тож у цій статті зможу оглянути лише частину з них.
Одними з перших хочу поговорити про голосових асистентів. У минулих статтях я не раз згадував випадки, що траплялися через розумних помічників, але жодного разу не торкався того, як вони влаштовані. Тема досить обширна, тож у цій статті розберу лише влаштування їхнього голосу.
І почну, мабуть, з помічника, чий голос ви, напевно, вже чули, Яндекс Аліси.
2017 — Яндекс Аліса
Хочу почати з цього асистента, оскільки моє знайомство з розумними чат-ботами почалося саме з неї. Тоді відповідь асистента здавалася мені чимось дуже крутим і інноваційним. Підкупало ще й те, що голос не лише відповідав на запити, але й мав особливе почуття гумору. Звісно, до Марвіна з «Автостопом по Галактиці» ще далеко, але на той момент це дійсно було в новинку.
Аліса з'явилася в 2017 році і стала проривним кроком для Яндекса в плані нейронних мереж. На той момент у них вже був проект Yandex SpeechKit, досить успішний сервіс з розпізнавання та синтезу мови, що працює на прихованих марковських моделях. Але їх не влаштовувала якість голосу, яке абсолютно не підходило для помічника, голос якого людина могла чути десять разів на день. Тому вони пішли іншим шляхом. Але це я забігаю вперед. А поки поговоримо про те, що, а точніше хто послужив основою для голосової моделі.
Як пам'ятаєте з минулих частин, для моделі потрібні вхідні дані, щоб було від чого відштовхуватися. Так було і тут. Голос Аліси заснований на популярній актрисі дубляжу Тетяні Шитовій, яка читачеві може бути знайома за дубляжем Марго Роббі (Харлі Квінн), Емми Стоун (Круелла) та Скарлетт Йоханссон (Чорна Вдова). Примітно, що раніше Тетяна озвучила ОС з штучним інтелектом Саманту у фільмі «Вона». Інші її ролі можна почути в цьому відео.

В одному з інтерв'ю Тетяна згадувала перші місяці роботи над чат-ботом. Спочатку це був досить виснажливий процес, як для самої Тетяни, так і для працівників студії, оскільки записували все підряд, тому що ніхто не розумів, якою повинна бути Аліса, та й до того ж через монотонну роботу був великий відсоток браку. Пізніше тексти почали очищати і структурувати за тематикою (медичний корпус, художня література тощо) або інтонацією (наприклад, запитувальною). Їй доводилося озвучувати дуже об'ємний масив текстів: від окремих букв і слів до речень. Хоча чому «доводилося»? Як ви пам'ятаєте, для кращої якості нейросетевої видачі потрібна навчальна база розміром «чим більше, тим краще», тому Тетяна і зараз озвучує асистента. За словами актриси дубляжу, цей процес безкінечний. ЄвропаПлюс наводить її слова
Я весь час, поки ще перший випуск «Аліси» писали, а це і так дуже довго тривало, я думала, що цю «книжку» ми закрили, і я пішла далі. Але мені мої друзі, які якраз і займаються цією технологією, ось вони мені сказали: «Тань, ти що, ти що! Все тільки починається!» А я кажу: «Як тільки починається, все вже закінчилося, все вийшло!» — і от немає, вже шостий рік йде, і до того, що ми її і зараз пишемо
Але це ми забігаємо вперед, давайте притормозимо і повернемося в 2007 2017 рік. Хочу нагадати, як Аліса звучала в той час
Як ви можете чути, її відповіді відрізнялися від нинішніх: відповідала нісенітницю, не запам'ятовувала нитку розмови, а її голос був ненабагато кращим за Glados з першого Portal, ніби клаптики фраз з'єднувалися в одне речення. Чому так? Відповідь знаходиться нижче.
Може виникнути питання: чому б їм просто не закинути все в нейронку і відразу не отримати потрібний звук? У той час технології на основі машинного навчання були все ще дуже повільними і не підходили для генерації в реальному часі. Про це компанія писала в своєму блозі.
Тоді якраз набирали обертів нейропараметричний підхід, в якому задачу вокодера виконувала складна нейросетева модель. Наприклад, з'явився проект WaveNet на базі згорткової нейросистеми, яка могла обходитися і без окремої акустичної моделі. На вхід можна було завантажити прості лінгвістичні дані, а на виході отримати пристойну мову. Першим імпульсом було піти саме таким шляхом, але нейросистеми були зовсім сирі і повільні, тому ми не стали їх розглядати як основне рішення, а досліджували це завдання у фоновому режимі. На генерацію секунди мови йшло до п'яти хвилин реального часу. Це дуже довго: щоб використовувати синтез в реальному часі, потрібно генерувати секунду звуку швидше, ніж за секунду.
WaveNet, про який згадується в цитаті, це проривна технологія анонсована компанією DeepMind (належить Google) у 2016 році. Вона могла видавати дуже реалістичне аудіо (причому не тільки голос, але й музику) і обганяла всі існуючі на той момент аналоги. У тому ж році Google опублікувала статтю про її роботу, де можете послухати приклади і порівняння з іншими типами синтезу.
Про розвиток WaveNet поговоримо в наступній статті, але найголовніше, що потрібно знати: якість виходу нівелювалося швидкістю роботи. Тому для Аліси цей метод не підходив.
Але що тоді робити? Рішили поєднати нейропараметричний підхід з іншим, який дозволяв швидко формувати і виводити фрази. А знаєте, як він називається? Я про нього, між іншим, у попередній частині говорив. Давайте нагадаю основні типи:
Вгадали, що використовували? Тоді давайте звіримо результати. Відповідь знаходиться в наступних словах з наведеного вище статті
Що ж робити? Якщо не можна синтезувати живу мову з нуля, потрібно взяти крихітні фрагменти мови людини і зібрати з них будь-яку довільну фразу. Нагадаю, що в цьому суть конкатенативного синтезу
Так, використовувався компілятивний синтез. Ось як ці два типи синтезу поєднували:
- Завдяки нейропараметричному синтезу, з нуля генерується мова. Отриманий результат досить поганої якості, але для своїх цілей цілком прийнятний.
- Алгоритм шукає в базі шматочків аудіо ті, які максимально близько будуть підходити до аудіо, згенерованому в першому пункті.
Подібний метод у ті роки застосовувався і іншими голосовими асистентами, будь то Alexa чи Siri.
Але поступово всі вони перейшли на технології на основі трансформерів.
Ви користуєтеся голосовими асистентами
2017 — Трансформери, об'єднуйтесь!
Що ви знаєте про трансформери? Якщо відповіли, що їх поставив Майкл Бей, і ви не бачите зв'язку з темою статті, то ви сильно помиляєтеся. Саме трансформери сприяли стрибкоподібному зростанню нейромереж, включаючи і ChatGPT. Мова, звичайно ж, не про автоботів, а про особливу архітектуру глибоких нейронних мереж, яка визначила їх подальший розвиток. Але що вони взагалі з себе представляють?

Для початку розберемося з поняттям глибока нейронна мережа (DNN — Deep neural network). Коли я торкався NetTalk, показував картинку з одним прихованим шаром, а от у глибоких нейромереж шарів у десятки і сотні разів більше.
До 2017 року більшість нейромереж обробляли вкрай маленький обсяг даних за раз, так як обчислення проходили послідовно, а не паралельно. Це можна порівняти з тим, як ви читаєте цей текст. Ви не можете одночасно читати і початок абзацу, і його кінець, адже навіть якби це було здійсненно, можете втратити нитку оповідання. Забув згадати, що ситуація ускладнюється важкою стадією Альцгеймера, через яку, читаючи цей абзац, начисто забуваєте, що було в попередньому. Так і з нейромережами. Вони не могли почати обробляти наступне обчислення, не знаючи результату попереднього, та й особливою пам'яттю не володіли, через що виникали проблеми з контекстом.
Але все змінилося в 2017 році, коли 8 дослідників з Google випустили наукову статтю, під назвою.... перш ніж продовжити, хочу, щоб ви були максимально уважні. Запам'ятайте: все, що вам потрібно, це — увага.
Тепер, коли з цими тонкощами розібралися, можемо продовжити розповідь про Алісу... Що ви кажете? Не згадав назву? Як?! Я її сказав, просто ви були неуважні. Так, наукова стаття називалася «Attention Is All You Need», що було посиланням на пісню «All You Need Is Love» групи The Beatles (ох вже ці айтішники. Люблять вони посилання всюди вставляти. Гвідо ван Россум, автор Python, підтвердить).
Що ж такого проривного було в цій статті? У ній була представлена нова архітектура, трансформер, яка могла одночасно працювати з дуже великим обсягом одразу. Вона заснована на технології уваги (attention), яка була представлена в одній роботі 2014 року. Щоб було більш зрозуміло, як це працює, повернемося до прикладу з читанням. Якщо дуже спростити, то якщо раніше ви читали послідовно і для прочитання статті йшло кілька годин, то тепер можете за менший час паралельно читати всі слова у всіх частинах цієї серії і при цьому ви запам'ятаєте і зрозумієте все, про що я писав (і навіть те, про що не писав, але про це поговоримо колись потім).
Більш детально про все це можете прочитати в детальній статті Wired або в її пересказі у Forbes. А щоб підвести підсумки цього блоку, згадаю про те, що більшість людей, які працювали над статтею, пішли з Google і зараз працюють у сфері трансформерів в інших компаніях або ж заснували власні. Примітно, що один з них перейшов до OpenAI і працює над Q*, прототипом загального штучного інтелекту (AGI), але це тема для іншої статті.
Технологія трансформерів дозволила значно здешевити і розширити можливості нейросетевого синтезу. Першим офіційним продуктом, де були впроваджені трансформери, став Google Перекладач у 2018 році. Та ж Яндекс Аліса перейшла на цю технологію значно пізніше, приблизно в 2023. А зараз розумний асистент повністю перейшов на YandexGPT. Ні, назва — не калька з ChatGPT (Ну, в більшій мірі). GPT розшифровується як Generative pre-trained transformer або Генеративний попередньо навченний трансформер. Це означає, що модель заздалегідь навчають на великому обсязі даних, на основі яких і відбувається подальша генерація.
Але крім винаходу трансформерів, 2017 прославився й іншим значущим подією, але про це поговоримо в наступній статті.
Підсумки
Ми розглянули зародження нейромережевого синтезу і те, наскільки по-різному його використовували. У наступній частині торкнемося теми WaveNet, поговоримо про те, як платформа для створення музики вкрала голоси виконавців і як ваш голос можуть клонувати.
Ви, напевно, могли запитати, а де ж, власне кажучи, жахи, заявлені в заголовку? На той час нейромережевий синтез тільки зароджувався, через що був занадто примітивним і доступним лише вузькому колу людей. Тому й конфліктів на цій основі не було, а загрози були чисто гіпотетичними.
Наприклад, в цьому дослідженні йдеться про підвищену ймовірність спуфінгу систем голосової верифікації з використанням HMM-моделей. Але з розвитком технологій синтезу та доступності нейронок загрози з теоретичної площини перейшли в реальність. Але про це ми поговоримо в наступній частині.
Післяслово
Нарешті дописав!!! Ця частина далася куди складніше інших. Мій гуманітарний мозок відмовлявся розуміти технічну інформацію. Виявилося, що ранні нейронки були по-справжньому колосальними проектами, які вимагали багато часу, сил і винахідливості. Сподіваюся, вам було цікаво читати цей опус. Звісно, далеко не все, про що хотів поговорити, вдалося торкнутися в статті, сподіваюся, в наступній частині це вдасться. Якщо ж помітили, що десь помилився або щось не врахував, або просто хочете поділитися думкою — пишіть про це в коментарях, з радістю почитаю.
Як вам стаття?


