
Жахи нейронних мереж. Частина 6: Типи синтезу мови. Від Стівена Гокінга до Хацуні Міку
 ithitym
ithitym
Навіть не сумніваюся, що ви не один раз чули синтезований голос. Його використовують у навігаторах, автоответчиках, для оголошення зупинок тощо. Ми настільки часто його чуємо, що вже сприймаємо як належне. А цікаво, як це все працює? У цій статті я простими словами розповім про типи синтезу мови та способи його застосування.
Ця стаття — частина циклу, який присвячений моїй нейро-параної. З іншими можете ознайомитися за посиланнями нижче:
- Ужаси нейронних мереж. Частина 1: Нейромережі та авторське право.
- Ужаси нейронних мереж. Частина 2: На яких ваших даних навчаються нейромережі.
- Ужаси нейронних мереж. Частина 3: Як зробити шапочку з фольги або варто боятися ШІ?
- Ужаси нейронних мереж. Частина 4: Генерація та розпізнавання облич.
- Ужаси нейронних мереж. Частина 4.5: Clearview AI та помилкові звинувачення.
- Ужаси нейронних мереж. Частина 5: Розпізнавання мови.
Як ми дізналися з попередньої частини, розпізнавання голосу може нести свої ризики. Але часто ця технологія йде в парі з синтезом мови, про який і піде мова в цій статті.
Синтез мови — це відновлення форми мовного сигналу за його параметрами. Звучить максимально сухо, але саме така формулювання дозволяє зрозуміти, як цей синтез відбувається.
За останній час ця область зробила досить великий стрибок вперед. Досі пам'ятаю, як дивувався, коли чув живий голос Яндекс Аліси. Але час йшов, технології покращувалися, і тепер синтезувати голос може будь-яка людина, використовуючи готові бібліотеки. Але як ця технологія працює? Давайте розбиратися.
Хоча в назві є слово «ужаси», почати хочу з того, що дійсно багатьом приносить користь, а саме допомога людям з обмеженими можливостями. Насправді, це одна з небагатьох речей, які мені подобаються в штучному інтелекті.
Не так давно прочитав чудову мангу «Не бачу, не чую, але люблю» про осліплого через перевтомлення автора манги та глуху дівчину. Твір неймовірно зворушливий і так само сумний. Він спонукає до роздумів про те, як сприймають світ ті, хто відчуває його по-іншому.
Ми сприймаємо слух, нюх, мову та здатність бачити як належне, тоді як інший багато б віддав лише за можливість ще раз побачити обличчя рідних. Але, на щастя, прогрес не стоїть на місці, і зараз є досить багато функцій, які допомагають людям повернути втрачені можливості (або, принаймні, замінити на щось схоже).
Почну, напевно, з найвідомішого застосування синтезу мови.
Всесвіт Стівена
В 1963 році, коли Хокінгу було 21 рік, у нього виявили бічний аміотрофічний склероз (БАС). Це захворювання повільно вбиває рухові нейрони, поступово паралізуючи інфіковану особу. Лікарі давали невтішні прогнози. За їхніми словами, пройде всього кілька років, перш ніж хвороба вразить дихальні шляхи, через що пацієнт не зможе самостійно дихати і харчуватися. При цьому в його випадку на когнітивні здібності хвороба ніяк не впливає. Тобто абсолютно ясний розум опиняється в паралізованому тілі. У цього явища навіть є назва: Синдром закритої людини.
Хокінга це сильно підкосило. Молодий хлопець, який думав, що у нього все життя попереду, раптом дізнається, що у нього залишилося дуже мало часу. На щастя, хвороба прогресувала повільніше, ніж передбачали. Тож він продовжив займатися своєю улюбленою справою, фізикою і космосом. Зокрема, його зацікавили чорні діри.
Перші пару років він міг ходити, спираючись на тростину, але пізніше хвороба прикутала його до інвалідного візка. Незважаючи на це, він залишався життєрадісною особистістю, з якою було приємно спілкуватися. Навіть будучи в інвалідному візку, Стівен Хокінг умудрявся швидко пересуватися територією університету, через що отримував попередження.
Ходили чуми, що він спеціально наїжджав на ноги тих, хто йому не подобався, включаючи принца Чарльза. Проте сам «гонщик» спростовував це твердження, заявляючи: «Це зловмисний слух. Я переїду будь-кого, хто його повторить».
Його біографія досить цікава, і хотілося б про нього написати ще більше, але, на жаль, тема статті не сам учений, а його візок і встановлені на ньому пристрої. А що стосується його історії, рекомендую подивитися це відео.

Я ж хочу зупинитися на системі, за допомогою якої він міг говорити, будучи майже повністю паралізованим.
У 1985 році під час поїздки в ЦЕРН Хокінг захворів пневмонією. Хвороба для ослабленого тіла була настільки серйозною, що його підключили до ШВЛ, а самі медики не вважали, що він піде на поправку. Страшно уявити, що відчувала його дружина, коли лікарі запропонували їй відключити чоловіка від апарату. На щастя, він вибрався, але втратив можливість говорити через проведену трахеотомію (коли в горло вставляють трубку, щоб людина могла дихати).
Спочатку для спілкування Хокінг використовував орфографічну карту, вказуючи на літери за допомогою підняття брів. Але цей спосіб був виснажливим і малоефективним, тому незабаром його замінили на спеціальне ПЗ Equalizer, яке працювало на Apple II, в парі з синтезатором мови від Speech Plus. Пізніше цю систему зробили переносною і адаптували під візок.
З часом він змінив програму на EZ Keys з ручним перемикачем. Таким чином, учений за допомогою клікача міг «друкувати» зі швидкістю 10–15 слів на хвилину, після чого синтезатор перетворював текст у голос. Завдяки цьому він навіть міг виступати з лекціями. Стивен заздалегідь готував матеріал, розбивав на абзаци, а потім зачитував його своїм новим голосом.

«Людина не тільки хоче, щоб її розуміли, але й не хоче звучати як Міккі Маус або далек»
У 1997 році Хокінг познайомився з співзасновником Intel Гордоном Муром. Мур помітив, що вчений використовує систему на базі процесора AMD 486, і жартома запитав, чи не хоче той перейти на «справжній комп'ютер», що працює на процесорі від Intel. Таким чином, Intel взяла на себе турботу про забезпечення професора найновішими розробками і оновлювала його комп'ютер кожні кілька років.
До слова, на сайті Intel є про це замітка, датована 1997 роком.
Єдине, що інженери не чіпали, це плата синтезатора мови Speech Plus CallText5010, розроблена ще в кінці 80-х (пізніше Хокінг перейшов на емулятор, що працює на Raspberry Pi), і ПЗ EZ Keys (яке покращували по можливості). Хокінг з 80-х використовував вбудований у Speech Plus CallText5000 синтезований голос під назвою Perfect Paul. За стільки років він до нього так прив'язався, що, коли з'явилися нові синтезатори, які дозволяли «говорити» менш роботизованим голосом, він залишив свій «рідний». Для цього плату CallText5010 модернізували, додавши в нього голос з попередньої версії, 5000. Таким чином, «Perfect Paul» став асоціюватися з геніальним ученим. Унікальний випадок, коли синтезований голос став нероздільною частиною реальної людини.
До слова, плата Speech Plus CallText5000, що належить Хокінгу, виставлена в музеї, де її можна розглянути з усіх сторін.

У 2008 році хвороба ослабила робочу руку настільки, що Хокінг більше не міг використовувати її для керування синтезатором, тому його асистент розробив «щічний перемикач». Пристрій кріпилося до окулярів і за допомогою спрямованого вниз інфрачервоного променя могло вловлювати напруження м'яза щоки. З тих пір він міг серфити в інтернеті, проводити лекції і писати листи та книги, використовуючи тільки цей щічний перемикач.
Але з часом його здатність «говорити» почала знижуватися настільки, що до 2011 року він міг надрукувати тільки пару слів за хвилину. Такий розклад його не влаштовував, тому Хокінг написав листа Муру і поцікавився, чи можна це якось виправити. У відповідь до нього приїхала команда з Intel Labs, яка почала пошук інших варіантів взаємодії з пристроєм. EZ Keys хоч і мав базову систему прогнозування слів (вона схожа на підказки слів у клавіатурі телефону), дозволяв керувати курсором у Windows і серфити в інтернеті через Firefox, але ПЗ було вже дуже давнім, так що вимагалося щось нове.
До проблеми підходили з різних сторін. Інженери намагалися прикрутити відстеження очей, але заважали низько опущені повіки. Нейроінтерфейс також став проблемою. Система, ідеально працююча з членом команди, не хотіла працювати на Хокінгу. Перші спроби спростити набір тексту також були невдалими. Але врешті-решт було знайдено рішення.
У 2013 році у Хокінга з'явилася нова система ACAT (Assistive Contextually Aware Toolkit), яка дуже спростила його комунікацію з комп'ютером та оточуючими. Зокрема, використовували предсказувач слів від SwiftKey, додатково навчений на працях вченого. Це значно підвищило швидкість набору тексту.

Модернізації піддавалася і гаряче улюблена плата синтезатора мови. Компанія, яка її випускала, закрилася ще в 90-х, тому ні заміни, ні запчастин вже не було знайти. Та й сама система була громіздкою. Тому була розпочата розробка емулятора синтезатора на основі Raspberry Pi.
Детальніше про це можна прочитати в статті Stephen Hawking's Voice Emulator Project (там же знаходяться посилання на інші цікаві роботи).
Таким чином, на 2018 рік у Стивена Хокінга була наступна комплектація (перелік взято з його сайту):
- Емулятор Speech Plus CallText 5010, що працює на Raspberry Pi 3.
- Система ACAT від Intel.
- Особливі динаміки, розроблені Sound Research.
- Lenovo Yoga 260, Intel Core i7-6600U CPU, 512 GB Solid-State Drive, Windows 10.
- Інвалідний візок Permobil F3 від Permobil.
- Інші апаратні рішення від Intel.
Цими пристроями він користувався до самої смерті. На жаль, 14 березня 2018 року хвороба, поставлена півстоліття тому, все ж забрала життя геніального вченого. Він помер вдома, залишивши після себе троє дітей.
Щоб не закінчувати блок на такій сумній ноті, хотів розповісти про одну з його «витівок».
Стивен був схвильований теорією подорожей у часі. Щоб розставити все по місцях, він влаштував вечірку для мандрівників у часі, але запрошення на неї розіслав після її проведення. Захід (був) призначений на 28 червня 2009 року і пройшов у гордому самоті. З цього вчений зробив висновок, що подорожі у часі неможливі.
Хоча, як на мене, будь я мандрівником у часі, теж не пішов би. Я занадто багато дивився останнім часом «Доктора Хто» і знаю, до чого можуть призвести маніпуляції з часом. Пояснюю. Те, що на вечірку ніхто не прийшов, могло стати ключовою точкою в історії, завдяки якій могли початися процеси зі створення таких машин. А якщо б хтось з майбутнього прийшов на неї, це б порушило причинно-наслідковий зв'язок. Якщо що, я не мандрівник у часі (але від IBM 5100 не відмовився б).

Примітно, що на церемонію пам'яті можна було зареєструватися всім, хто народився до 31 грудня 2038 року.
І в завершенні блоку про геніальну людину (і для того, щоб знову зв'язати тему з ШІ), наведу його інтерв'ю 10-річної давності, в якому Стівен Гокінг висловлював побоювання щодо розвитку штучного інтелекту і поділився думкою про свою систему АСАТ. А ось тут частина про ШІ, але з російською озвучкою.

У відео можна почути голос «Perfect Paul». Для його синтезу застосовувався формантний метод. Не бійтеся незрозумілого слова, зараз все поясню.
Формантний синтез
Окрім нейромережевого синтезу (він же end-to-end, про який писав у попередній частині), є й інші методи генерації мови. У цій статті не зможу все торкнутися, тому розберу тільки деякі, які можна зустріти в повсякденному житті.
Синтез мови, що застосовується в синтезаторі CallText 5000, називається формантним. Якщо не заглиблюватися в деталі, то при формантному типі машина математично намагається відтворити звучання голосу, на якому вона була навчена. Наприклад, у вищезгаданому синтезаторі за основу «Perfect Paul» були взяті дані, отримані з зразків голосу розробника, Денніса Х. Клатта (Dennis H. Klatt).
Але як саме в 80-х, без нейромереж і всього іншого, змогли зробити такий синтез?
У попередній частині я згадував про фонеми — найменшу звукову одиницю в мові (для простоти будемо вважати їх рівнозначними літерам). Коли ми вимовляємо якусь букву, на спектрограмі це може виглядати як послідовність з сплесків і затухань звуку. Такі сплески називають формантами. Формантні частоти розташовуються в діапазоні від 200 до 2000 Гц. Для того щоб відтворити одну фонему, потрібно вказати кілька формант, зазвичай від 2 до 4. Наочно це можна побачити в цьому короткому ролику або на картинці нижче.
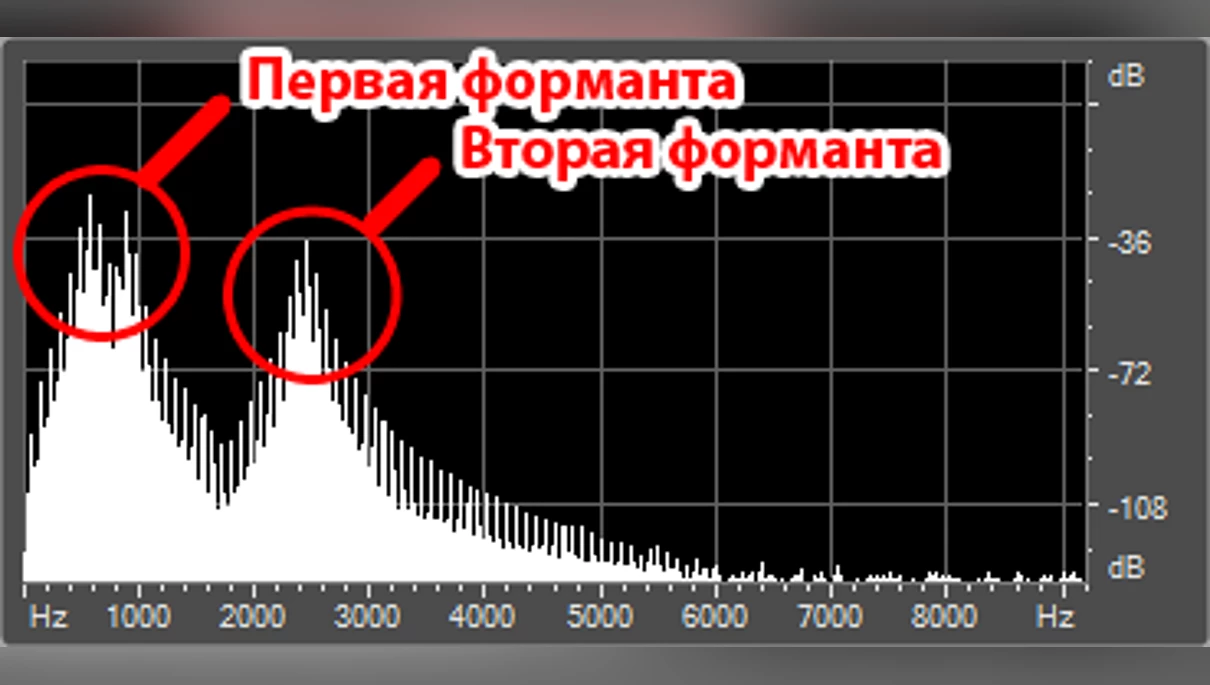
Ось як цей тип синтезу працює. На вході подається шум, який, проходячи через формантні фільтри, набуває звучання, схоже на голос. Це можна порівняти з нашою мовою. Ми виробляємо звук, який, проходячи через складну мовну систему, мовний тракт (набір фільтрів), перетворюється на зрозумілі слова. Це добре помітно на прикладі голосних. Спробуйте на одному подиху перейти від «а» до «о» і «у». Різні звуки отримуються внаслідок змінених «фільтрів».
Для наочності ось приклади значень для пари звуків.

Формантний синтез використовують у системах з обмеженою пам'яттю та потужностями, наприклад, у телефонних довідниках, музичних синтезаторах та пристроях для людей з обмеженими можливостями.
Більш детально про цей метод можна прочитати тут. Ну а ми рухаємось далі.
Зворотний зв'язок
Інший приклад використання синтезу мови для благих цілей є в більшості телефонів. Напевно, ви чули про функцію TalkBack в Android, яка дозволяє працювати зі смартфоном, навіть якщо людина слабкозора або повністю сліпа. Вона надає звукову інформацію про натиснутий об'єкт на екрані.

Для цікавості ввімкнув і спробував із закритими очима відключити цю функцію, орієнтуючись тільки на звукові підказки. Починав з головного екрану. Хоч елементи озвучувалися без проблем, було складно орієнтуватися у власному пристрої. Екран здавався занадто великим, і постійно забував, куди саме клікав. Зате є звукове супроводження при переході на інші меню, що допомагало орієнтуватися. Звичайно, цей «експеримент» не йде ні в яке порівняння з тим, що переживають реальні люди, які використовують TalkBack на постійній основі.
На відміну від попереднього прикладу, у TalkBack немає свого синтезатора. Він використовує Text-to-Speech-движок, який ви самі встановите. Що таке Text-to-Speech? Це синтез голосу на основі тексту. Це не окремий тип синтезу, а скоріше один із способів його застосування.
До слова, якщо ви читаєте цю статтю з браузера Microsoft Edge, то можете використовувати функцію «Прочитати вголос», яка також працює за принципом TTS. З її допомогою зможете перетворити довгий текст, як цей, в аудіоподкаст. На вибір надано безліч голосів різними мовами, але для російської та української мов голосів мало. Тільки по одному варіанту чоловічого та жіночого.

Приклад озвучки в Edge
Так про що я? Ах так! TalkBack!
За замовчуванням обрано синтезатор або від Google, або від тієї ж компанії, що і саме пристрій. Наприклад, на старенькому Samsung це «Модуль TTS Samsung». Але ви можете завантажити будь-який інший.
Зверніть увагу, що у стороннього синтезатора буде доступ до будь-якого тексту, на який ви клікнете. Т. е. це можуть бути паролі, дані банківських карток та інша інформація, що відображається на дисплеї. Ну, такий принцип роботи, і нічого не вдієш, окрім ретельного вибору постачальника TTS. Можете почати пошук з цього поста на «Реддиті», де обговорили пару таких додатків.
А я поки що зупинюся на розборі двох із них, які використовують різні підходи до синтезу мови.
Соло на Брайлівському дисплеї
Те, що викликає більше довіри, це RHVoice — безкоштовний синтезатор мови з відкритим вихідним кодом і без реклами. Доступен на Linux, Windows та Android. Розроблений при активній співпраці з цільовою аудиторією. Настільки активній, що сама засновниця та водночас програміст (Ольга Яковлева) є незрячою. Більш детально про це можна послухати на «Тифлостримі» і в цьому пості з Хабра: «Як сліпий розробник в одиночку створила синтезатор мови».

Українською та російською мовами доступний досить широкий вибір голосів приємної якості. На російській більше всього сподобалися Seva та Artemiy, а на українській — Marianna та Anatol. Слова вимовляються одразу після кліку на елемент екрана, без жодних затримок.
Ознайомитися з демонстрацією роботи можна в цьому гайді по установці RHVoise на Linux.

В описі ролика є текстова інструкція по установці, що включає команди для терміналу
Подробиці цього шикарного додатку розберу в іншій статті, а поки хочу поговорити про метод синтезу, який в ньому використано.
Згідно з цією статтею на Хабрі, тут використовується параметричний синтез, що працює зі схованою марковською моделлю (СММ). Понапридумують всяких слів, потім гуманітаріям розбиратися. Не лякайтеся складних назв, зараз все поясню.
Суть СММ у передбаченні послідовних невідомих параметрів на основі відомих. Таким чином, параметричний синтез передбачає благозвучну послідовність звуків, спираючись на сам текст, знаки пунктуації та правила побудови слів.
Наприклад, візьмемо слово «лапідарний», що означає «короткий», «стиснутий», «ясний». Ми не знаємо, де ставити наголоси, але помічаємо, що воно благозвучно звучить, якщо поставити його посередині. Це спостереження зробили на основі схожих за побудовою слів (наприклад, «ламінарний»). Також ми знаємо, як це слово схиляти, хоча ніколи його не бачили. Так само працює і параметричний синтез мови.
Але як саме він отримує зразок того, як має звучати правильний варіант? Пройдусь по етапах його навчання (дані взяті з вище наведеної статті, в якій торкаються етапи створення голосів для RHVoise).
- Збір правил побудови слів.
Першим ділом потрібно зібрати фонетичну систему мови. Т. е. правила побудови звуків, слів, речень, інтонацій, наголосів, список усіх звуків і т. д. В окремих випадках, якщо мова складна або маловивчена, такий збір може зайняти до півтора років. Наприклад, ось одна з подібних баз на GitHub. Таким чином створюється аналізатор мови, який за наявними вводами може розібрати речення на частини. - Підготовка речень для зачитування.
Тепер нам потрібні речення для подальшого зачитування, результат якого будемо розбирати за допомогою аналізатора. Предложения повинні бути побудовані таким чином, щоб охоплювати всі дифони, тобто всі комбінації переходів між фонемами. Дифони починаються в середині одного звука і закінчуються в середині іншого. Пропозиції можна написати самим, купити вже готові або скопіювати звідкись ще (наприклад, автори мовних моделей RHVoise брали їх з Вікіпедії. Хоча такий спосіб не працює з менш поширеними голосами через малу базу даних). - Створення мовної бази.
Диктор повинен чітким і беземоційним голосом начитати більше тисячі пропозицій. Варто зазначити, що цей процес досить тривалий, оскільки диктор може максимум 4 години на день зачитувати, не втрачаючи «чистоту» голосу. До якості таких записів ставляться дуже прискіпливо, щоб отриманий голос не «скакав» по тембру і діапазону. Тому компанії при виборі диктора роблять акцент не лише на красивому голосі, але й на вмінні дотримуватися певного тону для конкретної мови. - Аналіз мови.
Система (а часто й людина) аналізує записану мову, знаходить закономірності, виокремлює складові частини (тон, тембр, швидкість, форманти тощо), класифікує фонеми, їх межі, розташування один відносно одного та інше. Так у системи з'являються уявлення про правильне вимовляння фонем, так що вона зможе сказати навіть те слово, яке не входило в навчальну базу. Точніше, сказати ще не зможе, на даному етапі у моделі є тільки текст і аудіо диктора.Вона повинна кричати, але в неї немає рота. - Розмітка тексту і вибір відповідних звуків.
Далі запис розрізається на фрагменти відповідно до бази даних. Потім аналізатор мови з'єднує ці фрагменти разом, спираючись на граматику, структуру речення, члени мови, знаки пунктуації, паузи тощо. В залежності від усіх цих параметрів підбирається максимально близька за звучанням фонема. - Генерація мел-спектрограми.
Тепер у нас є текст для озвучення. У попередній статті я згадував, що при розпізнаванні мови звуки «перетравлюються» в мел-спектрограму, а пізніше в текст. Тут же відбувається зворотний процес. Текст перетворюється в цей особливий вид спектрограми, яка оптимальна для візуалізації людського голосу. - Синтез мови.
Передостанній пункт навчання — це безпосередньо сам синтез мови. Спеціальний механізм, вокодер, бере мел-спектрограму з попереднього пункту і перетворює їх в мовний сигнал. Таким чином у нас виходить кінцевий звук. - Корекція.
Заключною частиною є корекція і виправлення неточностей.
Часто недостатньо мати базу з правильним вимовлянням слів. Іноді потрібна допомога самих носіїв мови, щоб могли підкоригувати деякі місця і пояснити, що і де пішло не так.
Як бачимо, хоча процес досить складний і з купою нюансів, проте мова звучить якісніше, ніж при формантному синтезі.
Нейронний голос з глибин телефону
Окрім стандартних TTS движків, що працюють на параметричному синтезі, є й ті, які використовують нейронні мережі, як, наприклад, sherpa-onnx. Мова генерується безпосередньо на пристрої, і якість звучання досить хороша. Але в цьому є великий мінус. На пристроях зі слабким процесором між тапом на екран і озвученням проходить від 2 до 8 секунд. За цей час можна й забути, куди і навіщо натискав. Хоча, може, на сучасних девайсах такої затримки й немає (швидше за все, так воно і є). Трохи детальніше про нейронний синтез розповім ближче до кінця поста, а поки ось коротка думка щодо голосів цього движка.
У програмі доступно 4 російськомовних голоси. Ірина звучить занадто роботизовано, Денис картавит (і як ніби звук з поганого мікрофона), Дмитро, здається, нормально говорить, але іноді закінчення збиваються, а у Руслана «мова» цілком непогана, але щось з закінченнями слів не так, і таке враження, що занадто великі паузи між ними робить.
Українських голосів доступно 2. У Uk_lada-x_low в цілому він хороший, нагадує голос ведучої новин, але з наголосами проблема. А uk_UA-ukrainian_tts-medium чомусь не запрацював. Замість озвучення видавав якісь завивання.
Моделі можна встановити, перейшовши на сторінку зі списком усіх версій програми і мовних пакетів(Алярм, сторінка ще довша, ніж ця стаття). Варто зауважити, що одночасно може бути встановлений лише один мовний пакет.
Якщо ж хочете тільки послухати, як звучать нейро-голоси, їх можна спробувати на спеціальній сторінці.
Який висновок з цього порівняння можна зробити? Якби мені знадобилася «говорилка», я б використовував RHVoise.
Я б міг і далі розповідати про те, як технології допомагають людям з обмеженими можливостями, але, на жаль, тоді відійду від теми в заголовку, та й стаття вже досить розтягнулася. Хоча дайте знати, якщо хочете про це прочитати. Дуже багато цікавої інформації знайшов, так що, якщо що, з задоволенням про це зроблю окремий випуск (хоча, може, навіть окремий цикл статей присвячу... Ну, подивимося).
Ви могли помітити, що пройшло вже більше половини статті, але жодних «жахів», обіцяних у назві, поки не було. Це пов'язано з методами, які обговорили. Ні параметричний, ні формантний синтез не звучать по-людськи, а отже, їх не можна використовувати для шахрайських схем (якщо тільки переозвучити відео зі Стівеном Хокінгом, використовуючи «Perfect Paul»). Але наступний тип, який розглянемо, підходить для імітації людської мови. Адже немає нічого більш схожого на людський голос, ніж він сам.
314 кабінет
Тип синтезу, про який піде мова, це комкатен... компакет... кон-ка-те-на-тивний, о! Краще буду використовувати альтернативне позначення, компіляційний (або компілятивний) синтез. Насправді метод його роботи набагато простіший, ніж назва. При такому підході голос не з нуля синтезується, а беруться заздалегідь записані зразки мови, з яких складаються речення. Голосові відрізки можуть містити як один склад, так і цілі слова або навіть речення.
Наприклад, у минулій частині я згадував, що для одного датасету використовували записи телефонних пранкерів про 314 кабінет. Примітно, що цей різновид знущань називається «технопранками». У них жертва спілкується не з самим пранкером, а з уривками фраз іншої жертви.
Наприклад, у випадку нижче пранкери зателефонували в військкомат і використали запис якогось сторожа.

Ось як це працює. Спочатку пранкер телефонує людям, ставить замість свого голосу уривки фраз інших людей і записує відповіді жертв. Наприклад, запис з фразами про 314 кабінет була зроблена під час спілкування співробітника військкомату з уривками мови т. н. «бабки АТС», взятими з відомого телефонного розіграшу початку нульових. Далі пранкер ріже розмову на фрази та складові частини, готуючи таким чином базу даних. Використовуючи отриманий «датасет», він телефонує іншим людям і відтворює отримані уривки мови попередньої жертви, більш-менш підходящі до поточної ситуації.
Особисто я не розумію, що смішного в знущанні над випадковими людьми. Найадекватніша реакція була у одного співробітника військкомату, якому вже не в перший раз телефонували. Він просто кладе трубку, не даючи пранкеру можливості збагачувати свою базу новими фразами. Хоча, той і на цьому зробив «контент».

Пробив номер з реєстрацією та СМС
Цікавий факт: поки це все гуглив, натрапляв на ботів, які за маленьку плату можуть зателефонувати на певний номер і включити один з сценаріїв на вибір. Хоча з прикладів, які бачив, там скоріше нейронний синтез, а не склейка фраз (але не виключаю, що і подібні боти є).
Тому не відповідайте на провокації телефонних хуліганів. Хоча, напевно, в останній час це і неактуально. Давним-давно вже існують програми на кшталт Getcontact, які запобігають спаму, показують, як номер підписаний у інших користувачів, і, звісно, поповнюють базу даними з вашої телефонної книги. За посиланням інструкція, як заборонити Getcontact це робити (вона була актуальна у 2023 році, як зараз з цим — не знаю). Ваші дані в подібних програмах можуть бути, навіть якщо особисто ви ними не користувалися, оскільки їх могли використовувати люди, у яких є ваш номер.
Наприклад, одні підписали вас як «Саша Слесарь», і тепер всім зрозуміло, ким ви працюєте. «Тато», «Чоловік», «Зять» розповідають про ваше сімейне становище, а «Пушкіна 30» — ваша адреса. І от таким чином, тільки на основі цих тегів, формується база, яка доступна всім бажаючим. За наведеним вище посиланням є інструкція щодо видалення інформації про ваш номер з їх баз.
Проміжні підсумки
Так, мені знадобився заголовок, щоб розділити теми пробивання номера і синтезу мови.
Т. е. компілятивний синтез мови — це склеювання записів голосу однієї людини (поєднання голосів різних людей — це вже RYTP). Наприклад, він застосовується для озвучування зупинок у транспорті або в синтезаторах вокалу. Що? Що таке синтезатор вокалу? Як добре, що ви запитали, якраз хотів про них поговорити.
Ultimate Sempai
Ура! Ось і добралися до моєї найулюбленішої теми. Стиль змінився, бо навряд чи хтось до сюди дійде, так що можна, не боячись, нести всяку нісенітницю! Для початку хочу поділитися одним роликом, щоб, якщо раптом хтось читає цей дурниця текст, міг налаштуватися на подальшу деграда шизо частину статті.

Ця пісня до вокалоїдів має таке ж відношення, що і Stronger Than You до Undertale.
Напевно, ви знали про існування вокалоїдів і, можливо, навіть чули деякі пісні, виконані неіснуючими аніме-дівчатами. Ні? Хм, тоді коротко поясню.
Vocaloid (vocal + android) — це програма від компанії Yamaha, через яку будь-хто* бажаючий може створити синтетичний вокал на основі тексту. Для цього використовуються войсбанки (voiсebank) — набір даних, що містить у собі як вокальне звучання всіх варіацій фонем і складів, записані співаком або сэйю, так і словник для правильного перетворення букв в окремі фонеми. На даний момент доступна шоста версія програми з можливістю безкоштовного місячного пробного періоду (для її активації не вимагається вводити дані картки, як це зазвичай буває в подібних «безкоштовних» періодах).
Також в народі під словом «вокалоїд» можуть розуміти не тільки саму програму, але й синтезовані голоси для неї. Хоча коректніше називати їх войсбанком (VB) або віртуальними співаками.
До слова, VB можуть записуватися сторонніми фірмами. Так, наприклад, відомий віртуальний виконавець Хатсуне Міку (чий голос оснований на записах сейю Саки Фудзити) створений компанією Crypton Future Media (яка також подарувала світові не менш популярних Кагаміне Рін і Лен).
Голос Міку можна послухати в цій пісні:

Як можете чути, спів звучить дуже красиво. Міку була представлена ще в 2007 році, і з роками її голос ставав тільки кращим. Для порівняння, так вона співала 15 років тому, а так — в минулому році. Якщо хочете дізнатися, про що пісня, рекомендую цей кавер.

Віртуальні співаки їздять в турне, влаштовують концерти і збирають багатотисячні зали. Так, під час світового турне Miku Expo 2024–2025, Міку відвідала з десяток країн, розташованих на різних континентах: від країн Європи і Північної Америки до Австралії. Одне з виступів проходило в Сіднеї, і за заявою 9Honey, на ньому присутніми було до 9000 глядачів.
Ось як виглядав подібний концерт, що пройшов у Мехіко.

Для показу самої віртуальної зірки використовувався LED-екран, що розчарувало деяких фанатів, адже раніше застосовувалися красиві голографічні проекції, як показано нижче:

Тільки подивіться, як створюється ілюзія взаємодії зі сценою, починаючи з 7:14. А з появою бездушного телевізора посеред сцени офіційний тур майже не відрізняється від фанатських концертів. Хіба що аудиторія побільше і є живий інструментал. Для порівняння, ось так виглядав повністю безкоштовний концерт, організований у 2025 році фанатами для фанатів.

Та навіть концерт, організований однією людиною, виглядає досить круто. Тут автор використовував спеціальну конструкцію з натягнутою плівкою зворотної проекції. (За цим посиланням показано, як він її збирає).

З юридичної точки зору у таких концертів все прозоро. Дозволи у творців Hatsune Miku, т. е. компанії Crypton, потрібно запитувати тільки якщо хочете використовувати персонажа в комерційних цілях (на платних концертах або в рекламі).
Тим не менш персонажів можна використовувати в рамках партнерської програми YouTube, без попереднього погодження з компанією. Наприклад, так Pinocchio-P у своїх кліпах використовує чібі-версію Міку. І ось посилання на кавер (а ви думали, навіщо я стільки води розлив? Все, щоб поділитися улюбленими треками).

Але такі правила стосуються тільки самого персонажа. На вокал жодних обмежень немає. Якщо у вас є ліцензія на голосовий банк, можете вільно її застосовувати в комерційних цілях, де тільки побажаєте. Наприклад, для озвучки власних пісень з оригінальним персонажем, як в цьому випадку.

Зроблю невелике відступлення (моя стаття, що ви мені зробите... А, ну так, читати припиніть. Не припиняйте, пж), щоб окремо і кавер показати. Неймовірно шикарний переклад і вокал. Шкода, що у автора так мало підписників.

UPD. Перед самою публікацією, на офіційному каналі Хатсуне Міку з'явився ролик з нещодавно проведеного JAPAN LIVE TOUR 2025 ~BLOOMING~. У ньому віртуальна співачка спільно з Касанэ Тето (уталоїд, спочатку створений як жарт на «2ch») виконує «MESMERIZER» (посилання на кавер). Для їх відображення використовувалися проектори, тому вони виглядають дуже живо і об'ємно.

Так, про що тема статті... А, точно! Синтез мови! Знову кудись не туди пішов.
Як вже казав, у вокалоїді синтез мови здійснюється шляхом склеювання фрагментів записів вокалу. У войсбанк входять як самі фонеми, так і звучання переходів між ними (щоб можна було, як у пазлі, з'єднувати одні фрагменти з іншими). У туторіалі, наведеному нижче, на позначці 7:58 можна почути приклад записуваних даних.

Більш детально про типи голосових банок можна прочитати в цьому розборі від UTAU-спільноти. Що таке UTAU? Це назва стороннього синтезатора, що працює за тим же принципом, що і Vocaloid, тільки поширюється умовно безкоштовно (також є повністю безкоштовний проект OpenUtau). Якщо що, за сам «Vocaloid 6» і 22 войсбанки до нього просять $225 (а додаткові голоси продають в основному за $90 — $100). Може, для відомих композиторів або гуртів це ще нормально, але для ентузіастів і любителів ціна досить кусюча.
Тим не менш, така ціна може бути пов'язана з їх якістю. Уталоїди ж (VB, зроблені для UTAU), хоч і в більшості своїй безкоштовні, звучать значно гірше. До речі, голосові пакети можуть бути і російськомовні. Наприклад, ось компіляція звучань 29-ти таких VB.

Як можете чути, деякі співають цілком непогано (наприклад, M1NTO, CD_Rusya або Genki Tatsu, хоча останньому накинув очки за пісню, яку виконував), тоді як у інших було проблематично розібрати слова без звірки з текстом. Але тим не менш, іноді і з уталоїдів можна витиснути прекрасне звучання. Наприклад, у цьому кавері на «Прекрасне далеко» автор майстерно попрацював зі звучанням.

До речі, на відео показаний інтерфейс Utau. Він не сильно відрізняється від вокалоїда, тому коротко опишу принцип роботи. Та бігуча вермішель посередині кадру — доріжка вокалу. Кожен блок — окремий семпл звуку, який можна склеїти з іншими, змінити тональність, додати вібрато і змінювати як душі завгодно. Много про що ще хотів би поговорити, але, на жаль, пора б закруглятися, а я ще не згадав досить цікаву фішку вокалоида.
У пробному безкоштовному періоді «Vocaloid 6» доступні тільки моделі Vocaloid:AI, які працюють по четвертому і останньому типу, про який хотів сьогодні розповісти, нейронному. Найлегший для розуміння тип.
- Нейронці скармлюється датасет (в даному випадку записи співу співака, а не окремі фонеми. Записи робляться легально).
- Система аналізує стиль, особливості співу та інші фактори.
- На виході виходить дуже живий вокал, який можна сплутати з реальним.
Представили цю технологію досить оригінально, «воскресивши» голос померлої в 1989 році співачки Хібари Місора.

Голос звучить дуже чисто. Прям мурашки по шкірі (в усіх можливих сенсах).
Більш детально про останній розповім у наступній статті. А поки в якості затравки, залишу посилання на пісню, згенеровану в SunoAI.
Підсумки
У статті розібрав 4 методи синтезу мови з наочними прикладами. Підсумую:
- Фонемний — коли звук, проходячи через фільтри, перетворюється в зрозумілі букви.
Приклад: голос Стівена Хокінга, «Perfect Paul». - Параметричний — передбачає благозвучну послідовність звуків, спираючись на сам текст, знаки пунктуації та правила побудови слів.
Приклад: TTS, зокрема RHVoice. - Компилятивний — склейка з відрізків мови (складів і слів), що знаходяться в базі.
Приклад: Вокалоїди. - Нейронний — ІІ навчається на великій базі даних і намагається їй наслідувати.
Приклад: Хібара Місора (якщо ви просто прокрутили всю статтю і не знаєте, хто це, гляньте верхнє відео).
Післяслово
Нарешті дописав цю статтю. Діліться в коментарях про те, що думаєте щодо тем, торкнутим у ній, довжини полотна або тем, які хочете, щоб обговорив у наступній частині. Особливо цікавлять ваші улюблені пісні вокалоїдів.
Також хочу запевнити, що дана стаття цілком і повністю зроблена за допомогою нейронної мережі. Якщо точніше, то в процесі могло брати участь до 86 мільярдів нейронів (точну кількість, яка використовувалася для написання статті, підрахувати не представляється можливим).
Ну а на цьому в мене все. До наступної частини, якщо мене в дурку не упечуть.


