
Жахи нейронних мереж. Частина 5: Розпізнавання мови
 ithitym
ithitym
С допомогою технології розпізнавання мови люди перетворюють голос на текст, спілкуються з колонками та керують розумним домом. Але як це все влаштовано по ту сторону інтерфейсу і які ризики воно в собі несе? У цій статті обговоримо, як технологія розпізнавання голосу може не лише допомагати, але й шкодити (навіть тим, хто не користувався нею жодного разу).
Як випливає з назви, це п'ята частина серії статей, присвяченої недобросовісному використанню ШІ. З рештою можете ознайомитися за посиланнями нижче:
- Ужаси нейронних мереж. Частина 1: Нейромережі та авторське право.
- Ужаси нейронних мереж. Частина 2: На яких ваших даних навчаються нейромережі.
- Ужаси нейронних мереж. Частина 3: Як зробити шапочку з фольги або чи варто остерігатися ШІ?
- Ужаси нейронних мереж. Частина 4: Генерація та розпізнавання облич.
- Ужаси нейронних мереж. Частина 4.5: Clearview AI та хибні звинувачення.
У 4-й частині я детально розповів про те, як працює розпізнавання облич і як ця технологія застосовується в ряді країн. Обов'язково повернусь до цієї теми трохи пізніше, але поки далеко не пішов, хотів би поговорити і про розпізнавання іншого типу біометричних даних — голосу.
А я вас чую
Уявіть, що ви кудись поспішаєте. Часу мало, але потрібно написати довге повідомлення. Набирати вручну занадто довго, а зателефонувати немає можливості. Що в такому випадку робити? Як варіант, записати голосове. Однак співрозмовнику може бути незручно його прослухати. У такому випадку на допомогу приходить функція голосового вводу, основана на технології автоматичного розпізнавання мови або ASR (Automatic Speech Recognition). Вона перетворює вашу мову на текст. І співрозмовник скаже дякую (хоча не скаже. Він не буде знати, від чого ви його уберегли), і в разі чого можна відредагувати отриманий текст перед відправкою.
Також голосовий ввід застосовується для взаємодії з віртуальними асистентами на кшталт Siri, Alexa або Google Assistant. Вони можуть поставити таймер, зателефонувати, створити нагадування, навчитися на ваших даних, скинути почуте куди не треба і безліч інших корисних речей. Якщо що, останнє — не конспірологічні домисли, а цілком реальний сценарій.

Отже, в цьому році (2025 для людей з майбутнього) Apple виплатила $95 млн внаслідок колективного позову. Позивачі стверджували, що віртуальний помічник Siri активувався без ключової фрази, записував розмови та передавав їх рекламодавцям. Серед записів була й конфіденційна інформація, включаючи медичні дані. Записи збиралися до жовтня 2019 року, після чого Apple зробила участь у програмі добровільною. К слову, подібні інциденти, але без позовів, були і у інших компаній, включаючи Google (пару прикладів наводив у третій частині).
Розпізнавання мови є і в чат-ботах. Наприклад, функція «диктувати» в ChatGPT перетворює ваш голос у текстовий запит з розстановкою знаків пунктуації.
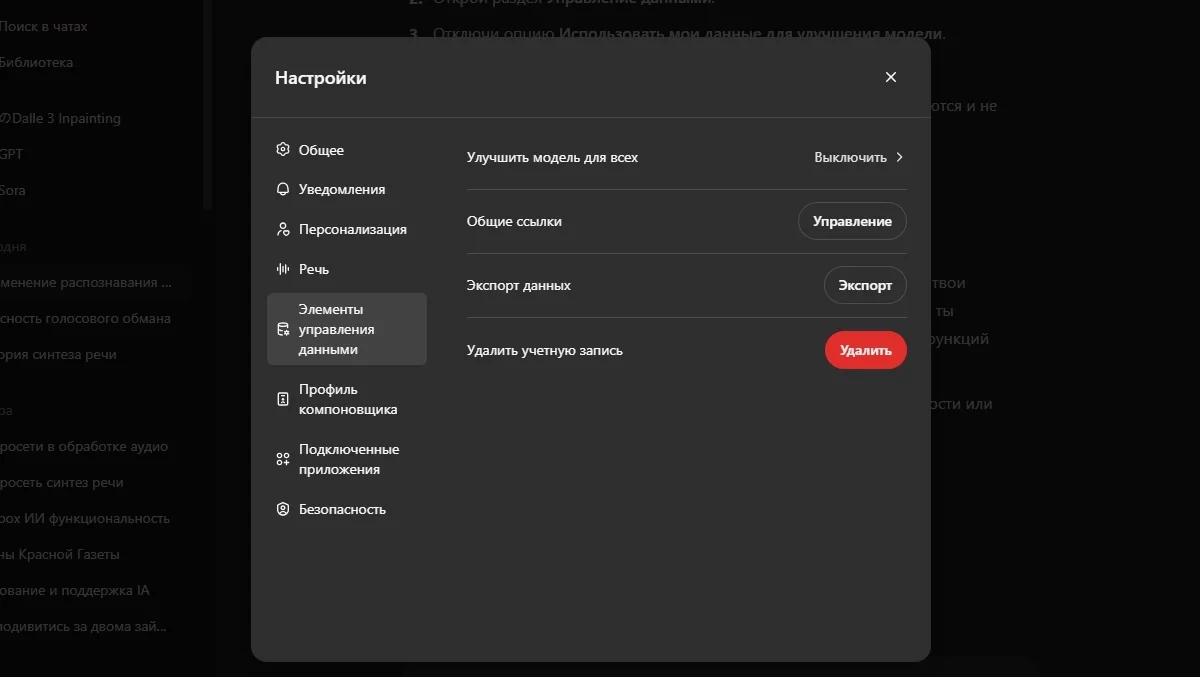
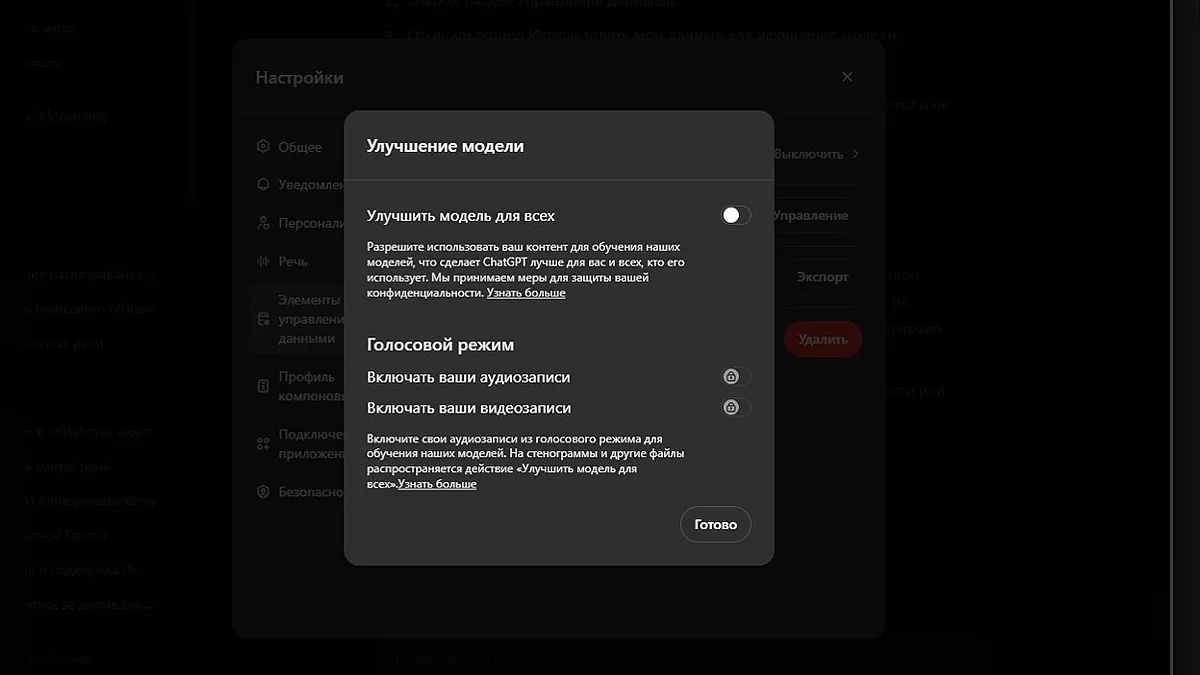
Як з'ясували в попередніх статтях, нейромережі навчаються на ваших даних, але в разі з ChatGPT йому можна заборонити це робити (принаймні, так стверджує сама OpenAI). Для того, щоб мало хто знайшов цю функцію, вона названа не зовсім зрозуміло: «Покращити модель для всіх». Розташована вона в Налаштування → Елементи управління даними → Покращити модель для всіх.
Але як алгоритм розуміє, що ви говорите? Давайте розбиратися.
Як згадувалося в попередніх частинах, нейромережі навчаються на наборі даних з текстовим поясненням до нього. Але в разі зі звуком є свої нюанси. Так само як картинка складається з пікселів, мова складається з фонем, окремих звуків, з яких будується слово. Нейромережа бере аудіо з його текстовим розбором, перетворює в зрозумілу їй конструкцію (найчастіше в мел-спектрограму), часто очищає від шумів, ріже на фрейми (короткі уривки по 10-25 мс) і шукає в них фонеми. Але так навчали моделі раніше.
Складність полягала в необхідності чітко позначати, в якому фреймі був вимовлений той чи інший звук. Це заняття нудне, довге і невдячне. До того ж різні люди вимовляють слова по-різному: з різною швидкістю, акцентом, чіткістю і т. д. Плюс іноді одна і та ж фонема може звучати по-іншому. Легше нагодувати нейромережу тонною всевозможних аудіо з транскрипціями, і нехай вона перетравлює собі на здоров'я, лише б потужностей вистачило. Такий підхід називається «end-to-end».

Але де знайти цю тонну записів?
Навчальний матеріал можна створити самому або ж, як і в разі з розпізнаванням облич, знайти спеціальний набір даних, зібраний за вас. Звідки зібраний? Тут досить багато варіантів.
Обнімашки!
Перш ніж почати, згадаю важливий момент при пошуку датасетів. А саме те, де їх шукати. За час дослідження найчастіше зустрічалися дві платформи, Papers with Code і Hugging Face. На першій можна знайти бази з різним набором даних, від відео і аудіо до графіків і зображень клітин. Але хотів би розглянути Hugging Face, оскільки він надає в рази більше матеріалу.
В цілому, якщо дуже коротко, то Hugging Face — це «GitHub для ІІ». На ньому зібрано безліч моделей і датасетів, які можна відфільтрувати за призначенням, мовою, вагою і купою інших параметрів. Також є Spaces — платформа для розгортання систем на базі машинного навчання. Простими словами, вона дозволяє запустити модель на серверах Hugging Face, де будь-який юзер може з нею взаємодіяти. Можливості у представлених моделей найрізноманітніші, від генерації картинок до клонування голосу (більш детально про синтез поговорю в наступних частинах).
В цілому досить зручний інструмент для публікації та пошуку необхідних баз. А тепер повертаємося до баз.
«Наш» датасет
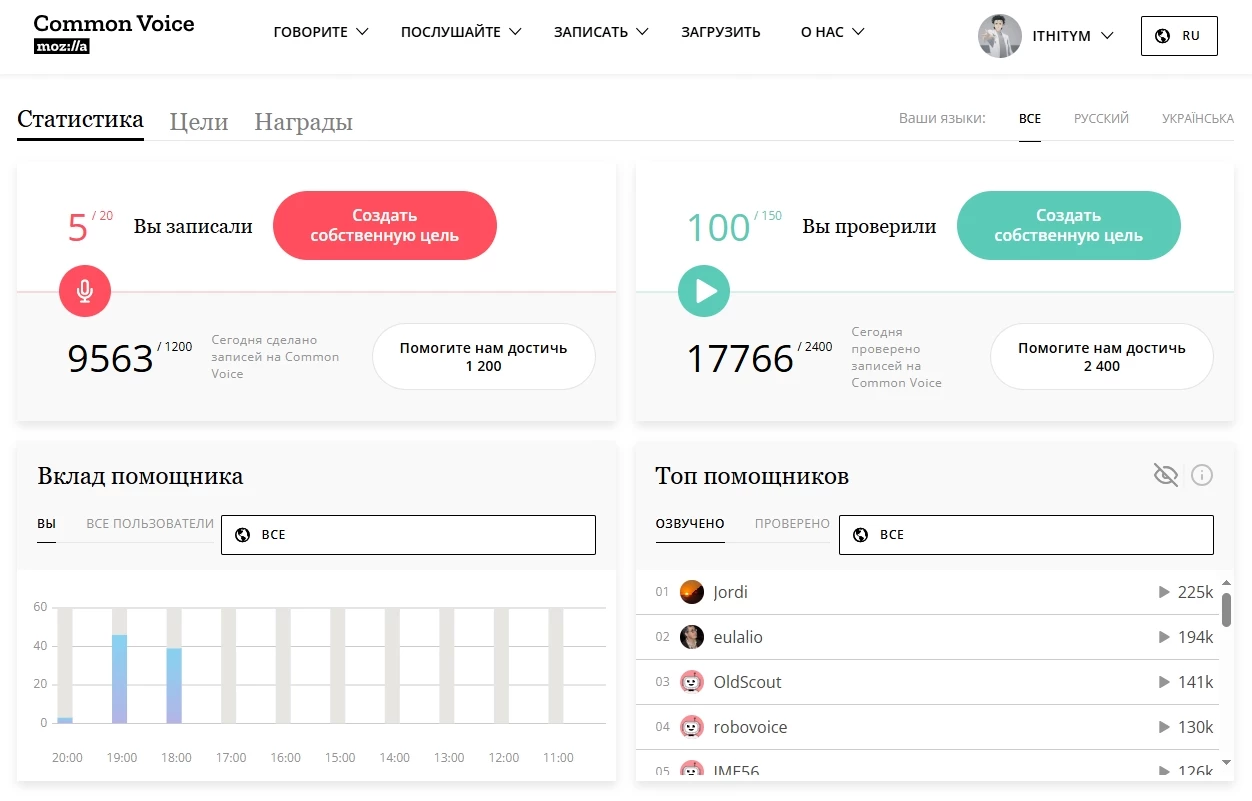
Хочу почати з краудсорсингового проекту Common Voice, заснованого Mozilla. Платформа дозволяє будь-кому внести свій внесок у розвиток громадського набору даних. Це можна зробити кількома способами: записати заздалегідь підготовлений уривок, перевірити запис іншої людини або запропонувати свій текст для озвучування. Всі зібрані дані формуються в датасет під ліцензією CC0. (Докладніше про типи ліцензій Creative Commons розповів у першій статті. Ну або просто можете перейти за посиланням на Вікіпедію). Завдяки цьому будь-хто може використовувати Common Voice для навчання моделей, включаючи і комерційні проекти.
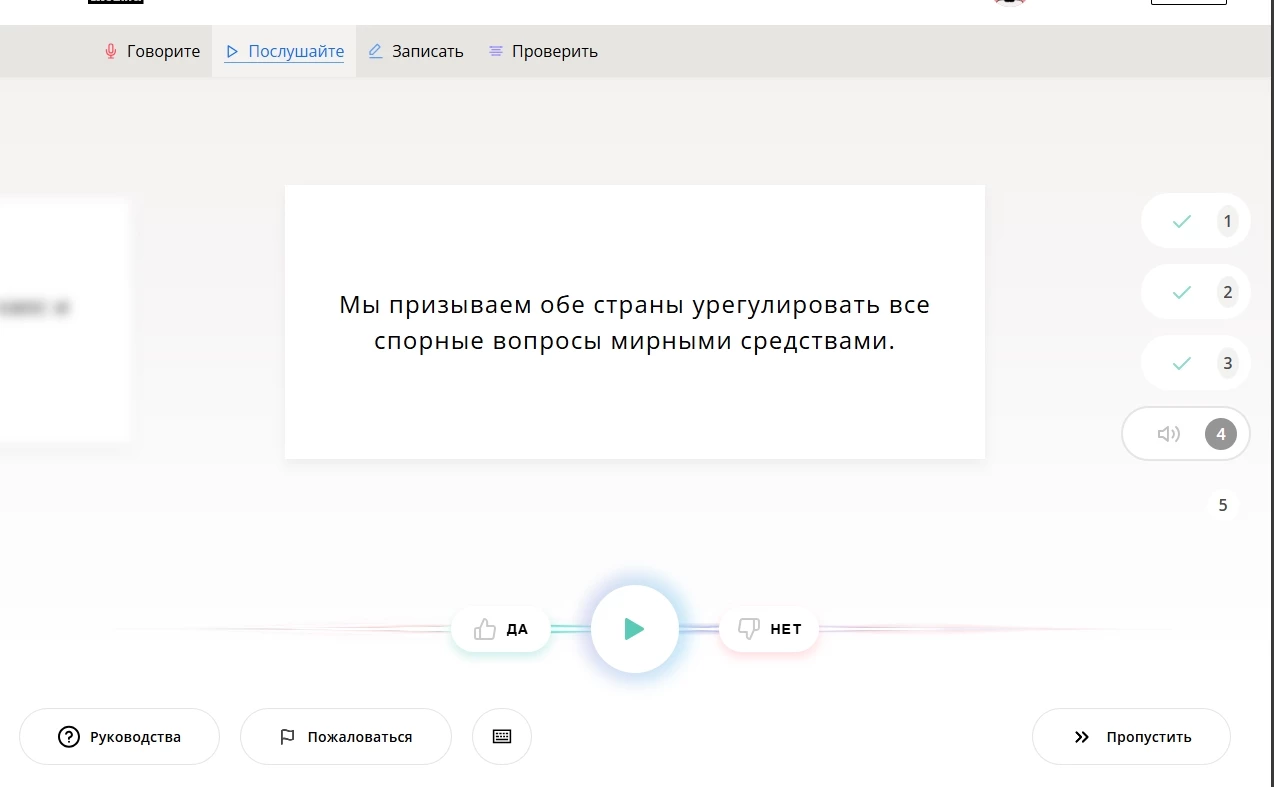
Реєстрація не складна, і інтерфейс інтуїтивно зрозумілий. Для цікавості перевірив близько 100 фраз і ось що з'ясував. Набір даних дуже різноманітний. Є як зашумлені, з нечітким вимовою, так і чисті уривки, зачитані з виразом (як ніби людина записувала уривок у перерві між театральною постановкою і створенням аудіокниги). Стать і вік також різняться (за весь час почув тільки 1 дитячий голос, але, на жаль, він допустив грубу помилку, так що відхилив його варіант).
І в плані ліцензій все добре. База поповнюється волонтерами, з інших майданчиків нічого не крадуть, запозичують і надають доступ до датасету всім бажаючим. Краса!
Згадався нещодавній новина (Антимонопольний процес проти Google може знищити Firefox), де згадується, що через цей процес можуть постраждати і некомерційні ініціативи Mozilla. А вони доклали руку до досить великої кількості проектів і досліджень, спрямованих в тому числі і на приватність (рекомендую прочитати їх статтю Accelerating Progress Toward Trustworthy AI). Буде прикро, якщо ці проекти закриють.
Текст, зачитаний по папірцю, це, звичайно, добре, але що робити, якщо хочеться більш різноманітних даних? Більш «живих».
Невелике відступлення
Замислювалися ви про смерть? Ну, не людську, а смерть сайтів, програм, ігор і т. д. Сайти закриваються, студії розоряються, а фільми втрачаються у часі або вважаються такими.
Так було з оригінальною українською доріжкою фільму «За двома зайцями» 1961 року. Довгий час фонограма вважалася втраченим, але в 2013 році її якимось дивом вдалося знайти в маріупольському фільмофонді. Правда, не в найкращому технічному стані. Умільці провели колосальну роботу з покращення звуку та картинки. З усім списком проведених маніпуляцій можна ознайомитися в описі фільму, завантаженого на Youtube.

Це приклад того, коли втрачену спадщину вдалося знайти. А скільки епізодів шоу та серіалів назавжди втрачені лише через те, що плівка вважалася ціннішою за вже записаний матеріал?
У 70-х роках плівки були дорогими, і простіше було перезаписати наявні, ніж купувати нові для кожної передачі. Приходить людина на склад, бачить плівку з пригодами космічного прибульця, що подорожує на телефонній будці крізь час і простір, і бореться з інопланетною солонкою з вінчиком і вантузом замість рук. Думка: «Ця наркоманія точно не стане в майбутньому популярною» і знищує серії «Доктора Хто» заради запису новин. Хоча в деяких випадках серії відновлювалися за аудіодоріжкою та збереженими кадрами (а іноді й цілі епізоди були врятовані завдяки фанатам, які записували серію на плівку).
Ось якби був якийсь архів, що зберігає файли та сайти до їх втрати... О! Так він є!
Олександрійська бібліотека ХХI століття
Вже більше 20 років працює некомерційний проект archive.org, на якому зібрано величезну кількість книг, відео, аудіо та програм для різних платформ. Особисто я його використовував у ковідні часи, коли потрібно було скачати .ipa файли для iOS7.

А з допомогою Wayback Machine можна переглядати ранній стан сайтів. Просто вставляєте посилання в поле, і відобразяться всі збережені знімки сторінки (якщо вони, звісно, є). Наприклад, отак виглядав Youtube у 2013 році.
Знімки корисні, якщо хочеться зберегти якісь дані до їх зникнення з сайту. Наприклад, цю функцію використовують при написанні розслідувань або статей для Вікіпедії. Сайти можуть закритися, видалити/змінити статтю, а веб-архів зберігає те, як виглядала сторінка у певну дату.
Я під час підготовки до попередньої частини шерстив веб-архів і в перервах проходив фанатські карти до шедевральної The Talos Principle. І от після чергової пройденої головоломки захотілося подивитися, як виглядав раніше VGTimes.
Стало цікаво, хто їх робить, тому вирішив заглянути в FAQ. Виявляється, є кілька способів, один з яких — команда добровольців, яка цим займається, Archive Team. Її мета — зберегти інтернет-спадщину, залишену людьми.
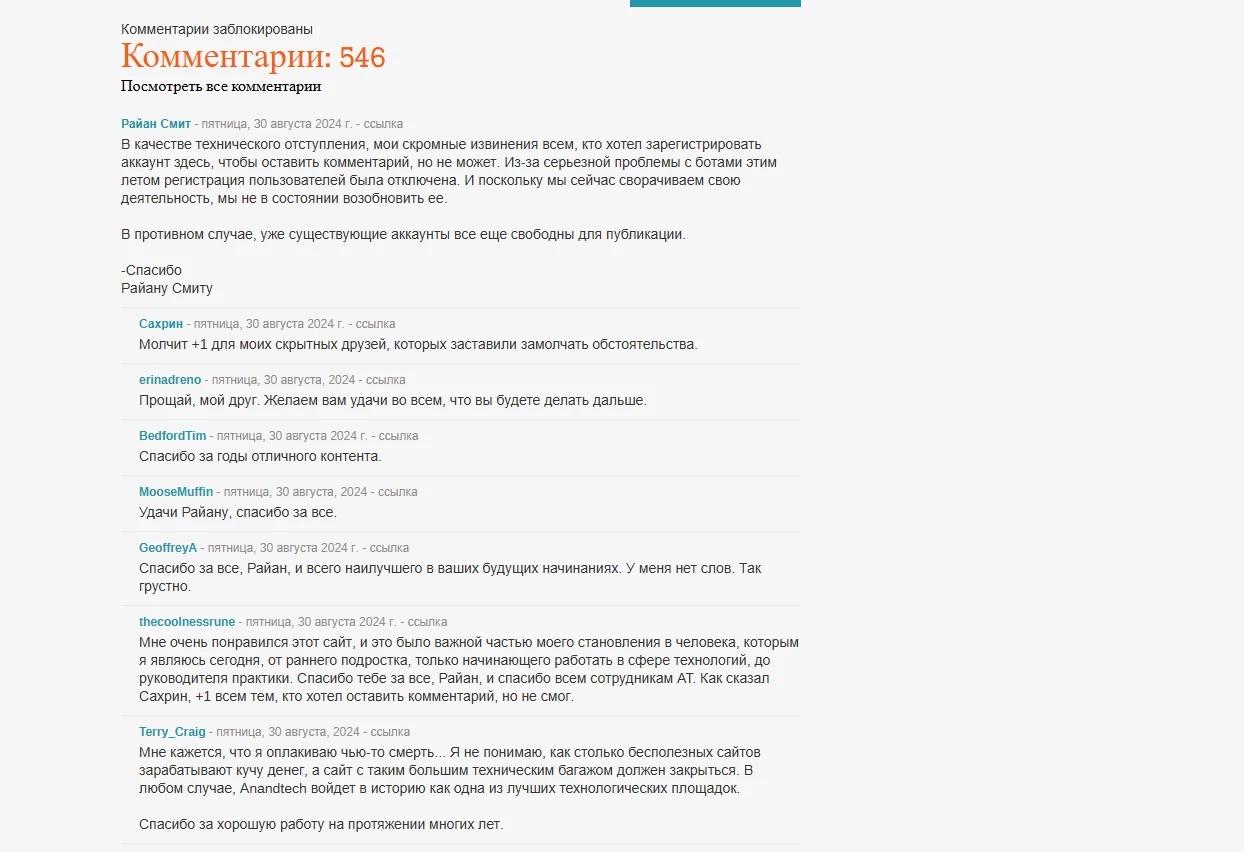
Один з розділів на порталі Archive Team — перелік сайтів, які закриті/незабаром закриються. З цікавості натиснув на одну адресу зі списку, яка закрилася в 2024 році. Це виявився, судячи з усього, досить значущий ресурс АnandTech, який з 97 року висвітлював події з світу електроніки та комплектуючих.
На ньому в закріпленому пості висить фінальний пост про закриття, в якому головний редактор, пропрацювавши там 19 років, дякує багатьом людям за допомогу та підтримку, ділиться думками та підводить підсумки. В ньому згадується, що їх видавець буде підтримувати сайт ще невизначений період часу, щоб люди могли читати ті тисячі статей, які були написані за ці роки. На цьому моменті відчув The Talos Principle experience.
Так от, для чого було це довге вступлення? Щоб показати масштаб проекту. В заголовку порівняв з Олександрійською бібліотекою не для красного слова (хоча і для нього теж).
І ось уявіть, що є багато даних, зручно структурованих у великі набори, та ще й з можливістю все це добро скачати. Що буде робити людина, яка хоче натренувати свою модель? Правильно, «прийшов, побачив, навчив».
Відголоски минулого
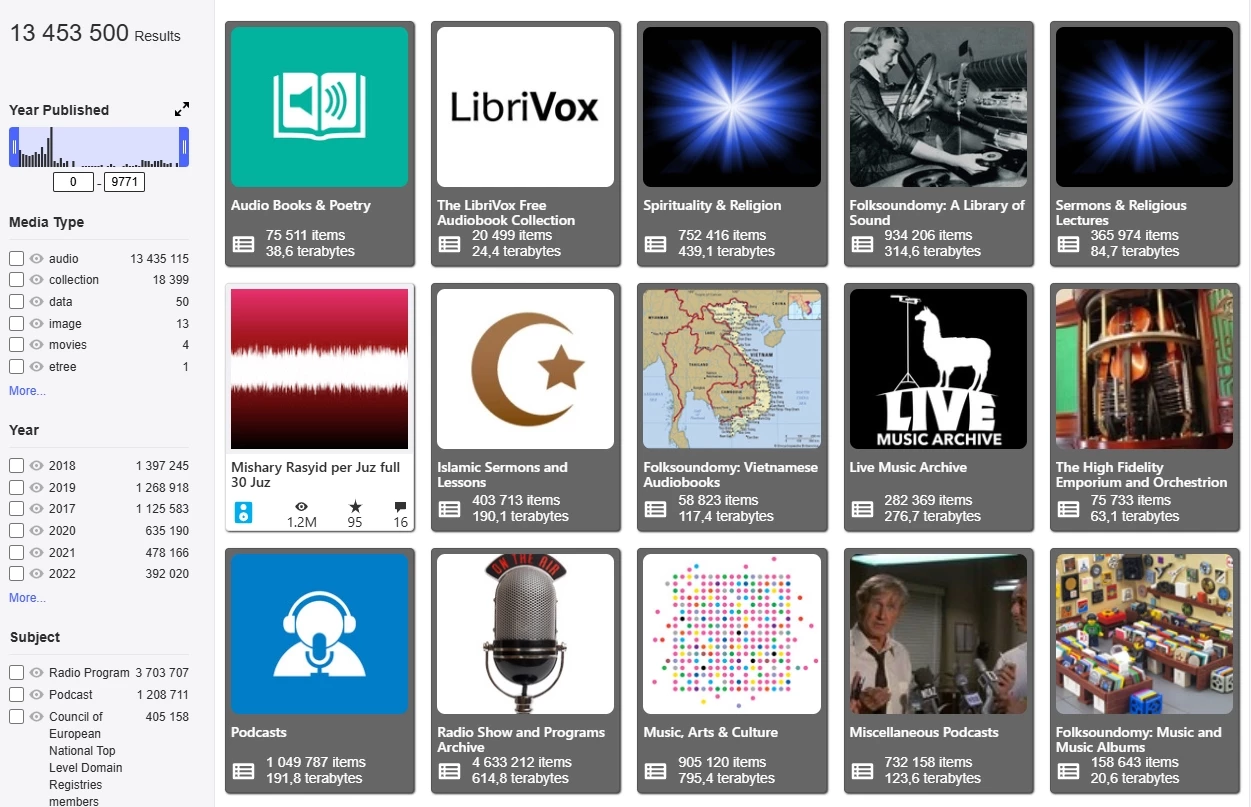
Датасет, про який піде мова, це Unsupervised People's Speech: A Massive Multilingual Audio Dataset. Набір даних вважається одним з найбільших і включає понад мільйон годин аудіо, взятих з Archive.org. У цьому наборі немає транскрипцій мови, тільки анотації щодо ліцензій (CC-BY-SA і CC-BY 4-ї версії). Також за допомогою Silero VAD була зроблена розмітка ділянок, в яких було виявлено голос, і прогноз мови кожного аудіо, зроблений за допомогою Whisper Large V3. Більшість файлів тривають від 3 до 10 хвилин, але деякі (14) перевищують позначку в 100 годин.
Збережи свій голос
У 2021 році Сбербанк випустив датасет Golos і відкрив його для всіх бажаючих. Частина набору складається з записів, зроблених на краудсорсинговій платформі (принцип роботи схожий з Common Voice), а інша частина складається з даних, записаних на студії та наближених до реального застосування. Так сказати, «в польових умовах». Звук записувався на пристрій SberPortal з різної відстані, а самі речення імітували запити до розумних пристроїв. Ліцензія є близькою до CC Attribution ShareAlike, але не є такою (посилання веде на текст ліцензії набору). Більш детально можна прочитати в статті на Хабрі, написаній одним з творців «Голосу».
У наведеному вище прикладі дані збиралися з згоди користувачів, і вони про це явно знали. Але є датасет, з яким все туманніше. А саме SOVA DataSet. Це відкритий набір даних, що містить в собі англійську та російську мову. Набір поділений на частини, взяті з різних джерел. Наприклад, RuYoutube містить записи з партнерських YouTube-каналів, а RuAudiobooksDevices — аудіокниги, записані на непрофесійну апаратуру. Вони збиралися при співпраці з авторами, і до них питань немає. Але мене привернула частина під назвою RuDevices.
Знайшов я її, коли шерстив HuggingFace на предмет датасетів підозрілого походження. На порталі можна прослухати приклади мови, і щось вони не схожі на те, що могло бути зібрано з добровільної згоди. Вони скоріше схожі на уривки голосових повідомлень: у багатьох є мат, мова жива, сторонні звуки на задньому плані і т. д.
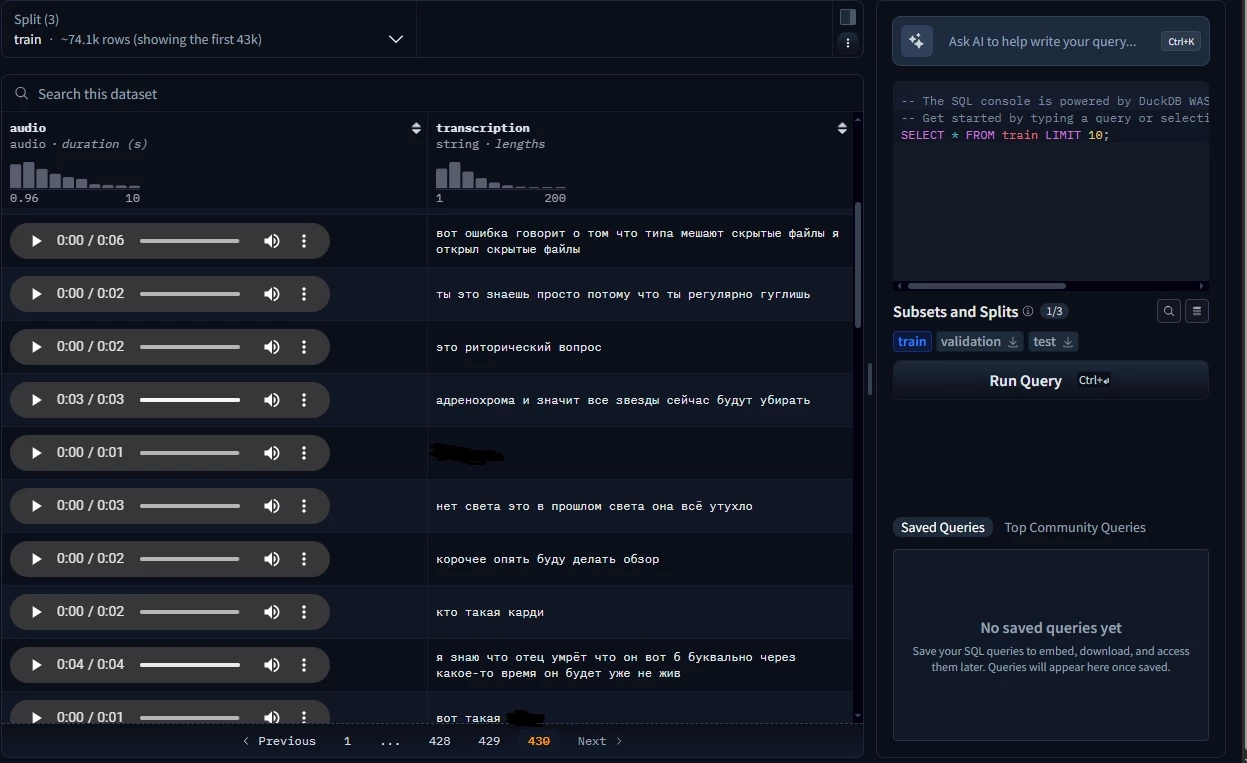
Було корисно дізнатися, як був зібраний цей набір. Світло на ситуацію пролила запис в блозі «Сови». В ньому компанія дає корисні поради тим, хто хоче навчити свою мережу, і розповідає, з чим їй довелося зіткнутися на цьому шляху. Зокрема, згадується, що для того, щоб модель краще справлялася, потрібно навчати її на даних, схожих з кінцевим завданням.
Оскільки SOVA надає чат-ботів для колл-центрів, то й навчати її потрібно було на даних телефонних дзвінків і краудсорсингу типу «Толоки» (але не на ній, оскільки не бажали ділитися даними клієнтів з Яндексом + хотіли мати зворотний зв'язок з тими, хто буде працювати з записами). Але де знайти записи телефонних розмов? Вони співпрацювали з колл-центрами і безкоштовно давали користуватися продуктом в обмін на дані для навчання.

Також у них є телеграм-бот @voicybot, який перетворює голосові повідомлення в текст. Бота можна додати в чати і налаштувати. Хоч на ГітХабі лежить його початковий код і на сайті бота сказано, що дані на серверах не зберігаються, але:
1. Бот надсилає посилання на політику конфіденційності, розташовану на сайті розробника. Стверджується, що ця політика єдина для всіх проектів автора, а значить, і бота теж стосується. В ній зазначено, що особиста інформація збирається для «надання та покращення Сервісів». Причому повного переліку того, що вважається «особистою інформацією», немає. Т. е. можна припустити, що вони використовують аудіо, надіслане в бот, для навчання моделі.
2. В коментарях до блогу самі автори прямо про це згадують.
...ми збирали свій [датасет] за допомогою компаній партнерів з кол-центрів і бота Voicy.
До слова, це була відповідь автору іншого великого датасету, Open STT.
У цьому наборі привернула увагу частина з телефонними дзвінками. Прослухавши більше 50 записів, стало зрозуміло, що в ньому використовувалися записи пранків, знущань над людьми. Хтось телефонував у державні органи, такі як військкомати, і під різними приводами намагався вивести співрозмовника з себе. Зокрема, багато разів згадувався 314 кабінет (як потім з'ясувалося, це досить популярна серія пранків, знущань).
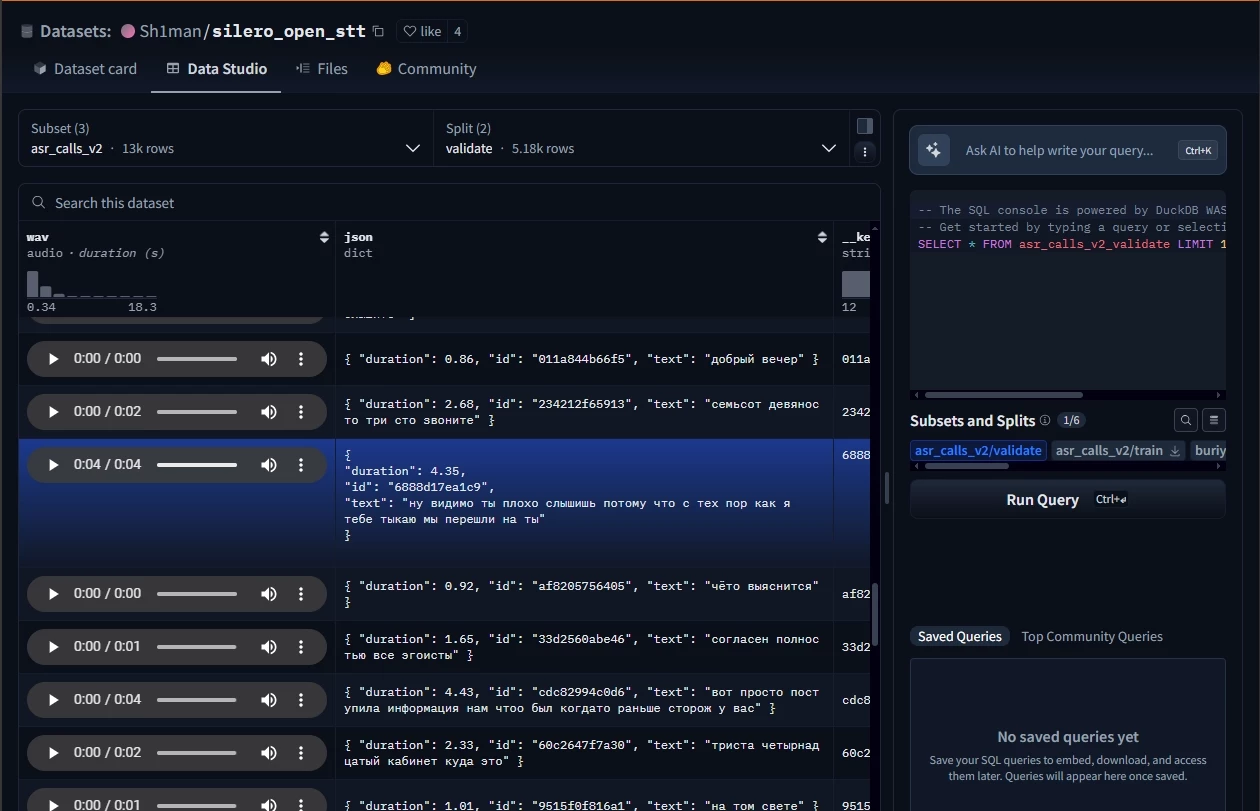
Стало цікаво, звідки взяті ці дані. Пошуки привели мене в блог одного з розробників. У ньому він розбирав критику щодо ASR-моделей і давав поради початківцям авторам. Зокрема, розбирався тезис «Створення продакшен-рішень на основі приватних даних, про що в самих публікаціях інформації дуже мало». Пізніше в статті автор визнається, що й їх компанія подібним грішить.
Ми використовували приватні дані для навчання своїх моделей, хоча розмір нашого приватного датасету менший за повний розмір датасету на порядок.
Далі наводиться список джерел аудіо, серед яких: «пранки», різні дзвінки (таксі, бронювання, комерція тощо), YouTube та аудіокниги. Останні два хочу розглянути детальніше.
З відповідей на коментарі під іншим постом стає зрозуміло, що книги були легально завантажені за абонементом. Правда, щодо YouTube-роликів все туманно. Автори впевнені, що використовують контент за принципом Fair use (добросовісне використання) і, оскільки розповсюджують його безкоштовно, нічого не порушують. Ось відповідь одного з авторів, написана іншому користувачу (який також занепокоївся питанням легальності збору деяких даних). Рекомендую прочитати всю гілку, там досить багато цікавого.
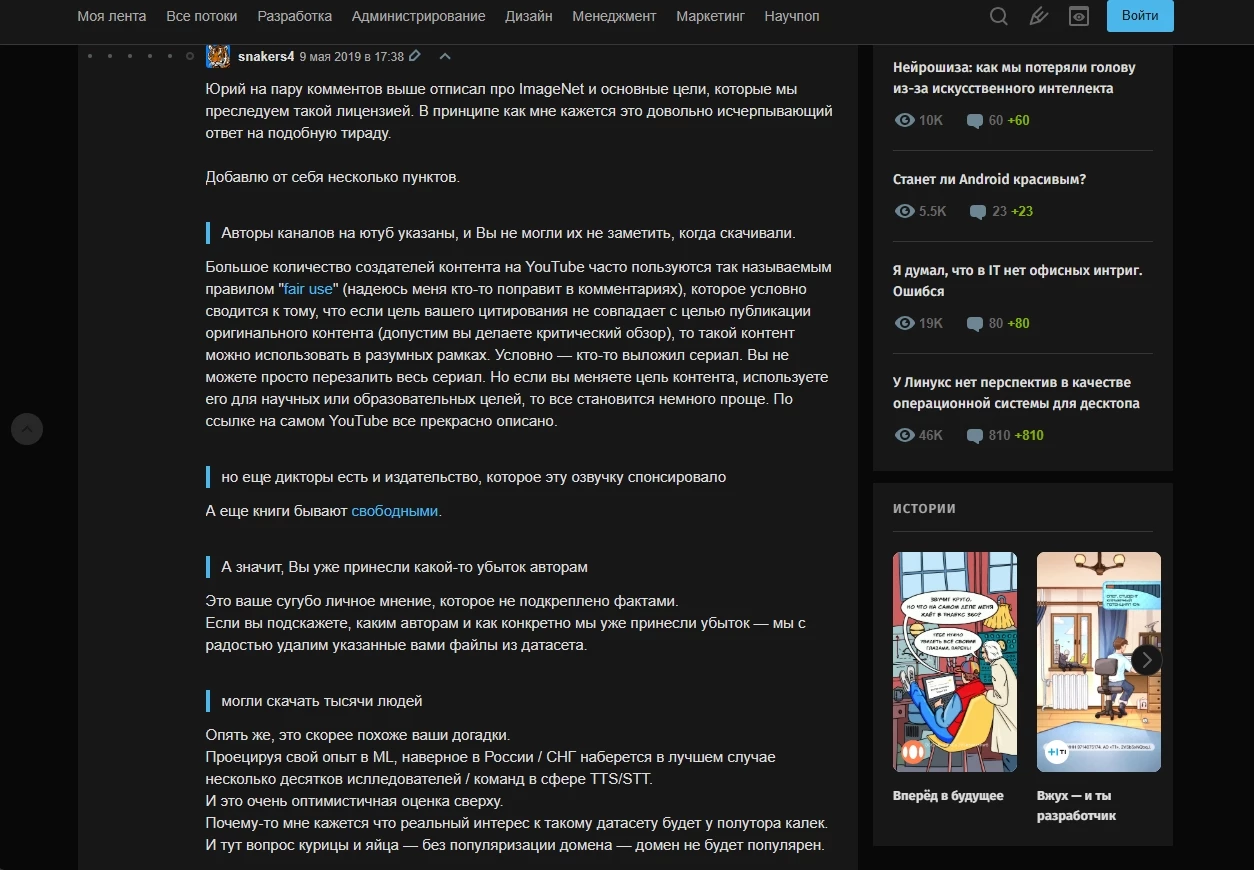
Ми знаємо, що можемо ненароком порушити чиїсь права. Але не знаємо, як масово опитати авторів, чи не порушили ми цього випадково. І, до речі, ми в одному човні з Youtube, Facebook, Habrahabr та іншими організаціями, які викладають контент користувачів, не перевіривши, які є у користувачів права на контент, але мають процедуру відкликання нелегально отриманого контенту.
Крім того, книги були завантажені мною легально за абонементом інтернет-бібліотеки.
На авторське право ми не претендуємо, книги не читаємо, читати і слухати аудіо користувачам не даємо (дані нарізані на фрагменти і розкидані по хешам — як документи після шредера), вважаємо, що збитків нікому не завдаємо.
Гарантій на дані ми не даємо. Ми пропонуємо ці дані для використання за fair use (див. коментар вище від snakers4), для наукових, дослідницьких і освітніх цілей або ж щоб користувачі використовували їх на свій ризик, в тому числі самі переконувалися в наявності необхідних ліцензійних угод на потрібне їм використання. Ми явно про це говоримо.
Ми не заробляємо на даних, але потенційно допускаємо можливість заробити на датасеті, і лише якщо в разі, якщо хтось інший на ньому заробляє гроші (про інші цілі ліцензії на «комерційне використання» я вище в гілці написав), всі тексти і аудіо користувачі можуть скачати і самі без нас.
Я був би радий, якби існувала процедура масово зв'язатися з правовласниками і запитати їх явне дозволення на наше нестандартне використання. Мені здається, багато хто буде за. Але вишукувати кожного автора в інтернеті самостійно у нас сил не вистачить. Якщо у вас є пропозиції, як це легко можна зробити — пишіть.
Ось у мене є канал на YouTube — але як там зі мною зв'язатися?
Але особисто у мене такий підхід викликає питання. Документи після шредера все одно можна відновити, записів це теж стосується. І те, що будь-хто інший може скачати ці дані, не скасовує факту, що це з труднощами можна назвати добросовісним використанням. Хоча якщо аудіо анотуються і трохи перероблені для більш ефективного скармлювання нейромережі, то з дуже великою натяжкою може підпадати під fair use. Але в такому випадку все одно залишаються питання до уривків з «пранків»... Сумнівно, але окей.
Ще багато є що сказати стосовно датасетів, але пост не резиновий (хоча взагалі-то резиновий, але полотно тексту навряд чи хтось читати буде). Головне, ми розібралися, звідки отримують навчальний матеріал.
На початку статті згадував різні варіанти використання ASR, тепер хочу поговорити про інциденти, які з ними пов'язані.
Алекса, купи слона
Бувало таке, що ваш голосовий помічник вмикався від стороннього голосу (будь то інша людина або ролик на YouTube)? Ні? Ну і добре. А от у когось було.
Як вже згадував, віртуальні асистенти можуть приносити користь. З їх допомогою можна ставити нагадування, здійснювати дзвінки і навіть управляти розумним домом. Але ще вони можуть здійснювати покупки. У більшості асистентів, окрім голосової команди, потрібно підтверджувати покупку іншим способом (кнопка «підтвердити», пін-код або щось подібне). Однак не у всіх ІІ-помічниках це є обов'язковим. Наприклад, Amazon Alexa дозволяє здійснювати замовлення навіть без підтвердження. Ось як це виглядає на практиці.

В ролику людина просить Алексу замовити ручку, і після уточнюючого питання замовлення оформляється. Це викликає занепокоєння, пов'язані з хибними спрацьовуваннями. Пристрій може почути щось не те, через що замовить непотрібну річ (за умови, що до нього прив'язана банківська картка і відомо місце доставки). Іронічно, що сам Amazon жартував на цю тему в одному зі своїх роликів.

На жаль, реальні випадки також мали місце.
Так, на початку 2017 року шестирічна дитина, граючи з Amazon Alexa, випадково замовила ляльковий будинок Kidkraft за 170 доларів і близько 2 кілограмів печива. Сам хлопчик заперечував, що просив у пристрою здійснити покупку, але згадав, що розпитував Алексу про ляльковий будинок і печиво. Можливо, бот неправильно зрозумів запит.
Найцікавіше сталося, коли про це дізналися новини. У репортажі CW6 ведучий сказав фразу «Alexa ordered me a dollhouse», після чого, як стверджується в наведеному нижче ролику, жителі по всьому Сан-Дієго стикнулися з непередбаченими замовленнями лялькових будинків.

Щоб такого не відбувалося, важливо вживати додаткові заходи обережності. Проте, у більшості асистентів вони вже за замовчуванням включені, так що це не така вже масова проблема (хоча пара інших випадків є тут і тут). А як бути з іншою функцією, яка не вимагає підтвердження?
Сам собі сваттер
За допомогою асистентів можна дзвонити не тільки знайомим, але й у служби порятунку. Хоча деякі пристрої такі дзвінки не підтримують (як, наприклад, станції Alexa, через особливості закону щодо VOIP-телефонії), але інші це дозволяють.
Наприклад, на «Реддиті» був пост про випадковий дзвінок у поліцію. За словами користувача, він дивився записи з відеореєстраторів на YouTube, і в відео був момент, коли водій чітко промовив «OK Google. Call 911» і його телефон, що лежав поруч, почав дзвонити на вказаний номер. Він встиг скинути дзвінок, але просив поради щодо подальших дій. Також до посту було прикріплено відео, яке він дивився.

Таймкод фрази: 7:44
Але це пост з «Реддита»... Без якихось доказів... От якби був задокументований випадок, тоді так... А він є.
Це сталося у 2023 році з Джеймі Аллейном (Jamie Alleyne). 34-річний спортивний тренер, займався з клієнтом у залі бойових мистецтв PTJ Gladesville. Він був шокований, коли до спортзалу під'їхали близько 15 поліцейських і пара машин швидкої допомоги. Правоохоронці стверджували, що отримали повідомлення про постріли.

Виявилося, що винна всьому була Siri, встановлена на Apple Watch тренера. Джеймі випадково її активував, поки займався з клієнтом. В цей час Джеймі кілька разів викрикував «1-1-2» (що є альтернативним номером екстрених служб) і підбадьорював клієнта, промовляючи «good shot». Швидше за все, оператор почув звуки ударів і крики і, вирішивши, що там йде стрільба, викликав медиків і поліцію.
Прибули поліцейські з розумінням віднеслися до ситуації, а сам тренер став вимикати Siri під час занять.
Висновок
На завершення хочу сказати, що, незважаючи на стільки негативних випадків, такі системи справді можуть врятувати життя. Наприклад, за допомогою функції SOS в Apple Watch, один чоловік, якого занесло на більше ніж 1,5 км від берега, зміг викликати рятувальників. Apple навіть про це ролик зняла.

Як і казав, це технологія. І, як і будь-яка технологія, вона може нести як користь, так і шкоду. А от чи перекривають плюси їх використання мінуси — кожна людина вирішує сама.
Післяслово
Ось і підійшла до кінця моя стаття. Спочатку планував торкнутися і синтезу, і розпізнавання мови, але занадто багато матеріалу відкрив. Завжди радий фідбеку в коментарях. Якщо щось не так висвітлив — виправте.
Чи сподобалася вам стаття? Діліться думкою в коментарях!
А на цьому в мене все. Побачимося в наступній статті!



